The Simple Abstract Domain
In LiSA, an abstract domain is responsible for tracking the whole program state,
including the values and types of variables and expressions, and the structure
of the memory.
To simplify this task, LiSA offers the SimpleAbstractState and the
SimpleAbstractDomain classes, that implement the framework proposed in:
Pietro Ferrara, 2016. A generic framework for heap and value analyses of object-oriented programming languages. Theoretical Computer Science, Volume 631, 2016, Pages 43-72.
DOI
In this framework, the state of the analysis is composed of a heap abstraction and a value abstraction, where the semantics of each instruction is first evaluated on the heap abstraction, that rewrites the instruction by removing all of the parts performing heap operations with symbolic identifiers. The rewritten expression is then processed by the value abstraction. Additionally, since processing assignments and allocations might summarize or materialize heap locations, the heap abstraction also provides a substitution (i.e., a series of assignments and variable removals) that must be applied to the value abstraction before processing the rewritten expression.
LiSA extends this framework by adding a type abstraction to the state, that is responsible for tracking the types of program variables and expressions. The type abstraction operates after the heap abstraction (i.e., after the rewriting happened), but before the value abstraction, so that the value abstraction can leverage type information to improve its precision if necessary. An intuitive scheme of how the framework operates can be seen below:
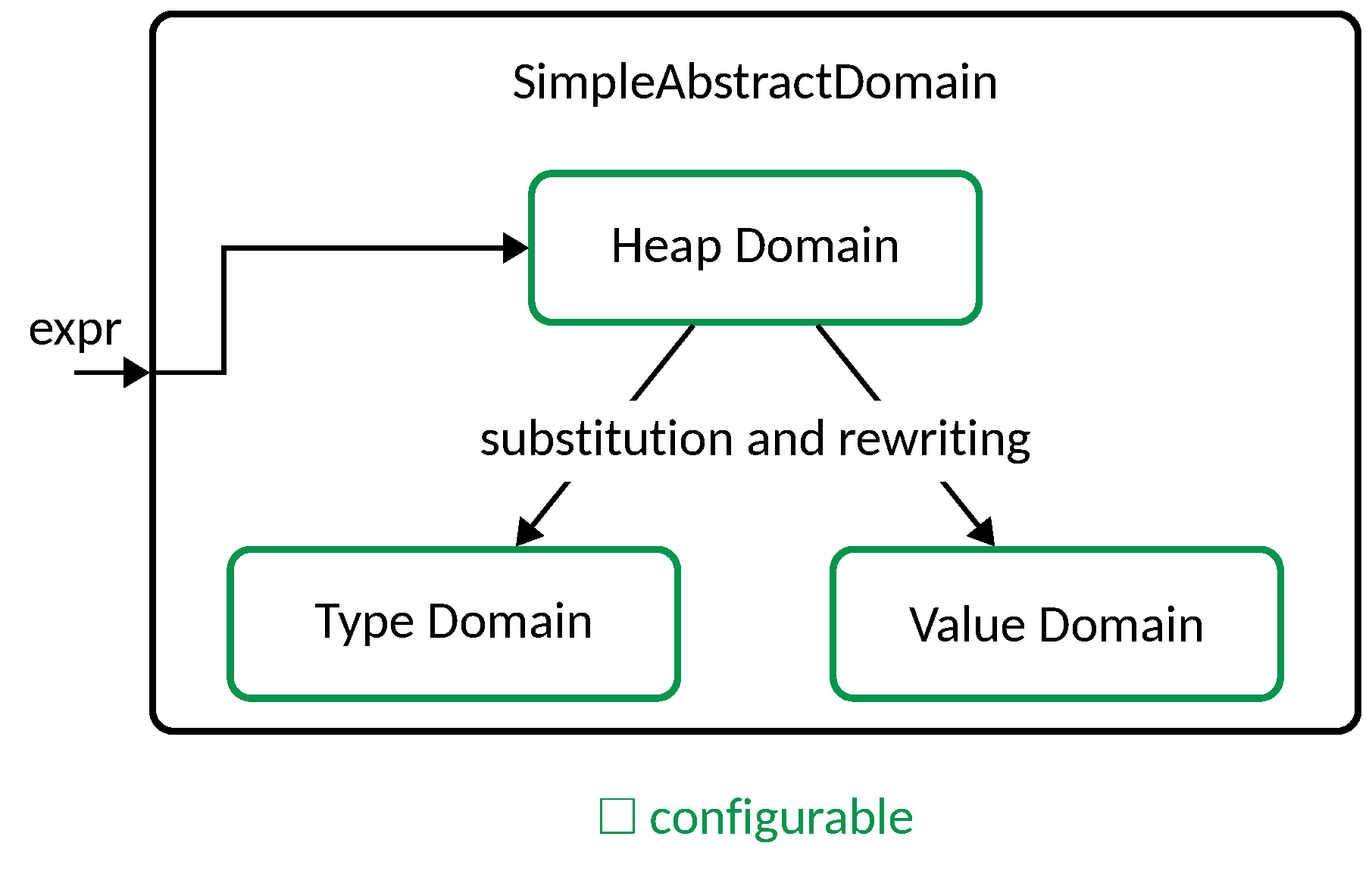
Intuitively, whenever an expression (assignment or not) must be evaluated, the
SimpleAbstractDomain first feeds it to the HeapDomain, the domain that
tracks the dynamic memory of the program. The HeapDomain processes the
expression, making the necessary updates to its internal state, and returns a
new state and a substitution, i.e., a list of operations of the form
{ x1, x2, ..., xn } -> { y1, y2, ..., ym }.
Each such operation should be interpreted as assigning to each yi all of the
values (i.e., their least upper bound) of x1, x2, ..., xn, and then
removing every xj that is not in y1, y2, ..., ym from the state. This allows
for easy summarization (i.e., { x, y } -> { x }, with x becoming the
summary of both x and y that are then removed from the state) and
materialization (i.e., { x } -> { x, y }, with y becoming a new
identifier that is added to the state with the same value of x).
The substitution is then applied to the TypeDomain, that updates its internal
state accordingly, and then to the ValueDomain, that also updates its internal
state accordingly. Finally, the HeapDomain rewrites the input expression by
removing all heap operations (e.g., if the HeapDomain knows that x.f is a
reference to some location l, then the expression y = x.f + 3 is rewritten to
y = l + 3: the memory access is removed, and the other domains can now focus
on variables only). This might generate more than one expression: both the
TypeDomain and the ValueDomain are fed one of them at a time, and their
resulting states are merged together through the least upper bound operation
to obtain the final states.
If you are not familiar with memory abstractions, concepts like summarization, materialization, and rewriting might be a challenge. Adopting this framework has the benefit of simplifying this: you can focus on implementing the value abstraction of your choice, and use one of the already-provided heap abstractions that LiSA provides!
As highlighted in the diagram above, the HeapDomain, TypeDomain, and
ValueDomain are all configurable, meaning that the SimpleAbstractDomain
can be instantiated with different implementations of each of these domains.
This page contains class diagrams. Interfaces are represented with yellow rectangles, abstract classes with blue rectangles, and concrete classes with green rectangles. After type names, type parameters are reported, but their bounds are omitted for clarity. Only public members are listed in each type: the
+ symbol marks instance members, the * symbol marks
static members, and a ! in front of the name denotes a member with a default
implementation. Method-specific type parameters are written before the method
name, wrapped in <>. When a class or interface has already been introduced in
an earlier diagram, its inner members are omitted.
Substitutions
In LiSA, a substitution is a list of HeapReplacement objects, each
representing an operation of the form { x1, x2, ..., xn } -> { y1, y2, ..., ym }
described above:

A HeapReplacement is composed of two sets of Identifiers, the
source set (i.e., { x1, x2, ..., xn } in the example above) and the target set
(i.e., { y1, y2, ..., ym } in the example above). The class provides
methods to retrieve these sets (getSources and getTargets), and to automatically
compute their difference, that represents the Identifiers that must be removed from
the state after the assignment (getIdsToForget). It also provides ways to add new
sources and targets to the replacement (addSource and addTarget, together with
withSource and withTarget that additionally return the current replacement
for chaining calls).
Lattice structure
The lattices managed by the SimpleAbstractDomain and its components are all
Domain Lattices
since they must provide the basic operations over variables and the scoping
logic other than lattice operations.
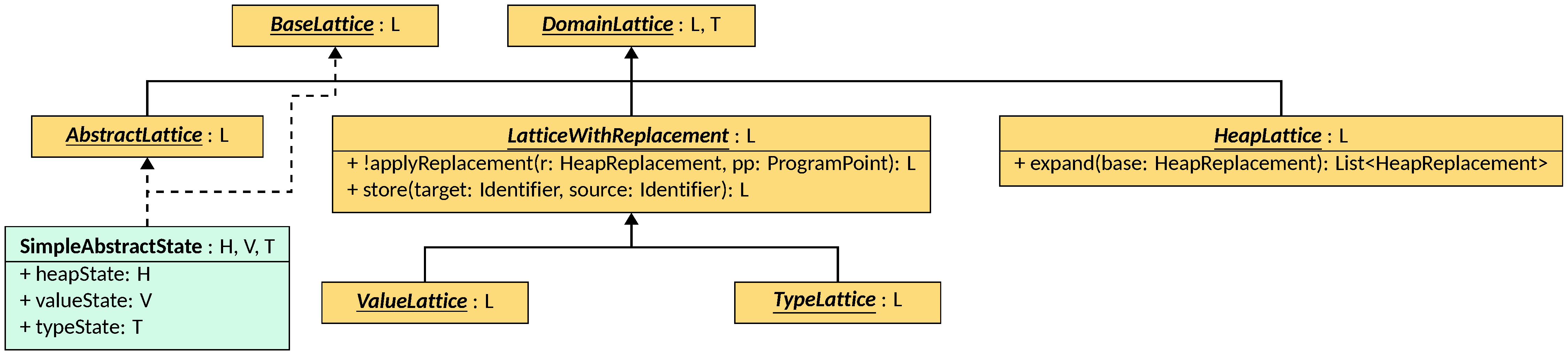
Specifically, the HeapLattice interface, parametric on the concrete type L
of the lattice, that must extend HeapLattice<L>, extends
DomainLattice<L, Pair<L, List<HeapReplacement>>>, meaning that lattice
operators accept and produce instances of L, but variable operations (like
forgetIdentifier) and scoping operations (like popScope) return both a
new and modified instance of L and a substitution, in the form of a list of
HeapReplacement objects. Other than the default
DomainLattice operations, HeapLattice defines a new method, called expand,
that is tasked with expanding a single deletion HeapReplacement (i.e., one of
the form { x } -> { }) with all the replacements implied by it (i.e., if y
is only reachable through x, then y must also be deleted). This is used to
ensure that no dangling references are left in the heap abstraction, performing
a sort of garbage collection.
Instead, LatticeWithReplacement defines a lattice instance that can be the
target of a substitution. It is parametric on the concrete type L of the
lattice, that must extend LatticeWithReplacement<L>, and extends
DomainLattice<L, L>, meaning that both lattice operations and variable/scoping
operations return instances of L. The interface defines the
implementation-independent logic for applying an individual HeapReplacement in method
applyReplacement. The latter relies on the store method to perform an
assignment. ValueLattice, parametric on the concrete type
L of the lattice that must extend ValueLattice<L>, and TypeLattice,
parametric on the concrete type L of the lattice that must extend
TypeLattice<L>, both extend LatticeWithReplacement<L>.
The DomainLattice instance that models the states generated by the framework
is SimpleAbstractState, parametric on the types H extends HeapLattice<H>,
T extends TypeLattice<T>, and V extends ValueLattice<V> of the
inner components to use. This class is effectively a cartesian product of the
three lattices, and implements the lattice operations by invoking the
corresponding operation on each component. Variable and scoping operations also
invoke the corresponding operation on each component, collecting all of the
substitutions produced by the heap component and applying them to the type and
value components. Note that no reduction is applied between the three components:
if one of them becomes bottom, the other two are allowed to remain non-bottom.
SimpleAbstractState implements both BaseLattice<SimpleAbstractState<H, V, T>>
and AbstractLattice<SimpleAbstractState<H, V, T>>, with the latter implying
that it can be used a lattice instance in conjunction with
Semantic Domains.
LiSA provides subtypes of
CartesianCombination
to quickly implement ValueLattices, TypeLattices, and HeapLattices as products.
Domain and Components
HeapDomains, TypeDomains, and ValueDomains cannot directly implement the
Abstract Domain
interface, since (i) abstract domains must be able to handle all symbolic
expressions, but ValueDomains and TypeDomains cannot, and (ii) since each
domain runs in isolation, they need avenues to query information from each other. To
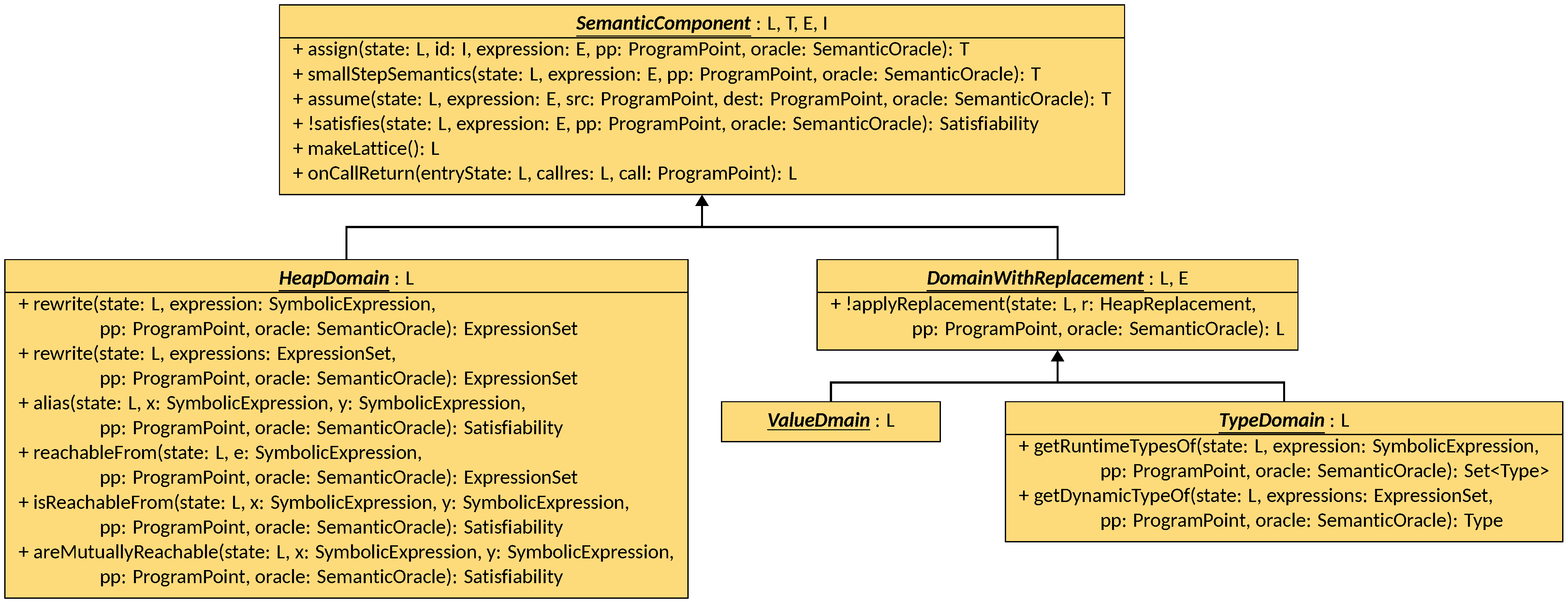
this end, LiSA introduces the SemanticComponent interface, that matches
SemanticDomain except for having an additional parameter, the
SemanticOracle, in all transformers:
The SemanticOracle parameter can effectively be used for cross-component communication,
exploiting the methods it exposes to query information from other components.
SemanticComponent has the same type parameters as SemanticDomain:
L extends DomainLattice<L, T>defines the type of abstract states the transformers accept as parameters (see the Lattices page;Tdefines the return type of the transformers (as, in some cases, a domain implementation might want to return a pair of a state and some auxiliary information);E extends SymbolicExpressiondefines the type of SymbolicExpressions the transformers can operate on;I extends Identifierdefines the type of Identifiers the transformers can assign values to.
HeapDomain, that has a type parameter L that must extend HeapLattice<L>,
inherits directly from SemanticComponent<L, Pair<L, List<HeapReplacement>>, SymbolicExpression, Identifier>,
meaning that its transformers accept instances of L as input, can process any
SymbolicExpression
and can assign values to any
Identifier,
but return a
pair of a new state L and a substitution List<HeapReplacement>.
ValueDomain, having a type
parameter L that must extend ValueLattice<L>, and TypeDomain, having a type
parameter L that must extend TypeLattice<L>, both inherit from
SemanticComponent, fixing its first two type parameters to L,
meaning that its transformers accept and produce instances of L,
its I parameter to
Identifier,
and the type parameter E to
ValueExpression.
The methods of a SemanticOracle are replicated and split among the three
components, each with an extra parameter for the state instance to use for the
computation and a reference to the SemanticOracle itself for further queries.
This allows domain-specific answers to each query to be computed modularly.
The SimpleAbstractDomain class can be defined in terms of these components:
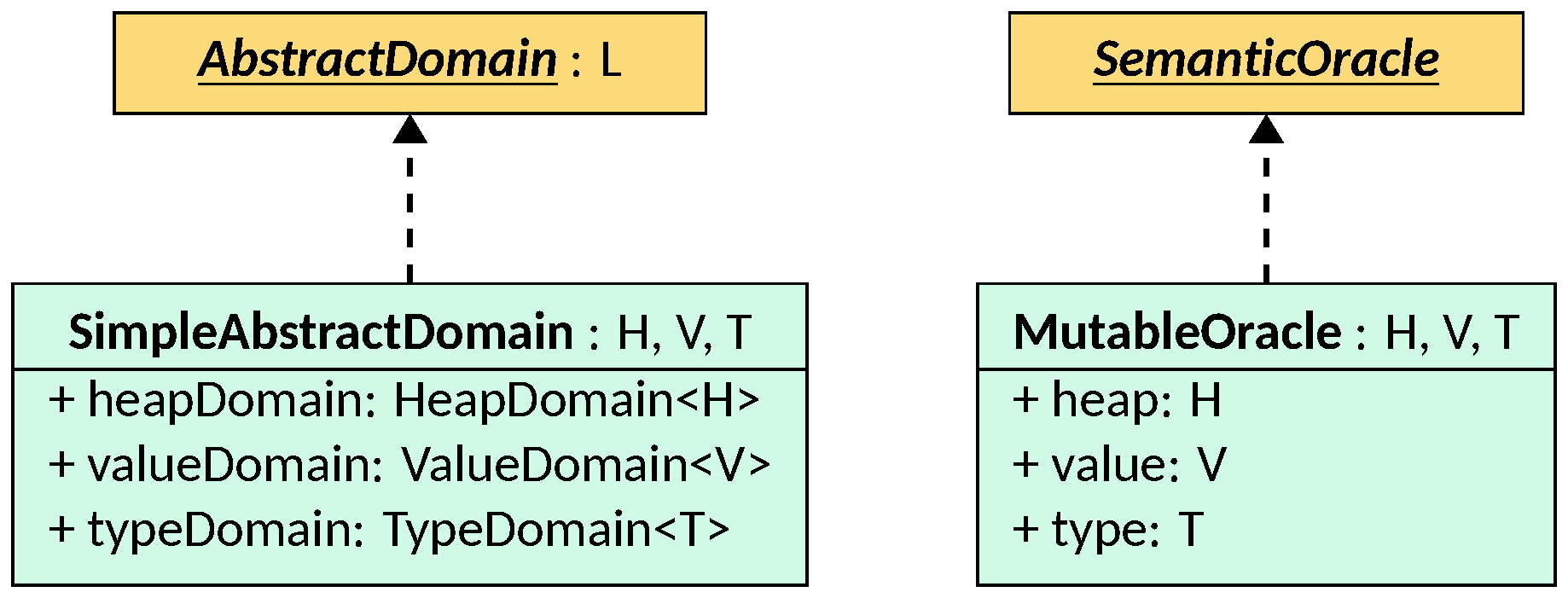
SimpleAbstractDomain, parametric on the types H extends HeapLattice<H>,
T extends TypeLattice<T>, and V extends ValueLattice<V> of the
states of its inner components to use, implements
AbstractDomain<SimpleAbstractState<H, V, T>> and stores the three components
to use in its fields. Each transformer is implemented
following the framework of rewritings and substitutions: first, the target
expression is processed using the corresponding heapDomain transformer over
the heapState of the current state, that returns a new instance of H
and a substitution. The substitution is then applied to the typeState and
valueState of the current state, updating them accordingly. Then, the
heapDomain rewrites the expression, and the resulting expression(s) are
processed one at a time using the corresponding typeDomain and valueDomain
transformers over the updated typeState and valueState. The resulting
states are merged together using the least upper bound operation to obtain the
final states.
The SemanticOracle created by SimpleAbstractDomain is the MutableOracle,
that holds the three states heap, type, and value to use for queries.
The oracle can be mutated (that is, each state can be updated) to avoid
excessive allocations during the execution of each transformer. In
MutableOracle, each query is implemented by delegating the computation to the
corresponding component, passing the held state and the oracle itself as parameter.
Thus, components always receive an oracle that has an overview of the whole program
state, and can query information from each other as needed.
For a list of heap, value, and type domains already implemented in LiSA, see the Configuration page.
The
HeapDomain interface is extended by BaseHeapDomain,
that provides default visiting behavior for the rewrite overloads. It is highly
advised to inherit from that interface whenever possible.
Whole-Value Analyses
The SemanticOracle interface has two special methods: hasWholeValueAnalysis
and constraints. These are used to implement the constraint-based information
exchange framework described in:
Luca Negrini, 2026. Whole-value analysis by abstract interpretation. Frontiers in Computer Science, Volume 7, 1655377.
DOI
The framework allows domains to query information from each other by generating
constraints (i.e., binary expressions) that constrain the possible values of
a target expression in a domain-independent way. For instance, a numerical domain
might want to evaluate the expression 1 + len(y), where y is string.
As the domain does not know how to evaluate len(y), when evaluating the
expression alone it has no other choice than returning the top element.
With this framework, the domain can (i) ask the oracle if the whole-value
analysis is enabled, and (ii) if so, ask the oracle for the constraints of
len(y). The returned constraints will be, e.g., { 2 <= len(y), 10 >= len(y)
}: these information is enough for the numerical domain to know that the
value of the expression lies between 3 and 11 instead of top. To enable
the whole-value analysis, one must use the WholeValueAnalysis class as
ValueDomain, passing at construction all the domains that should be part of it.
The methods defined by the ValueDomain interface follow this framework:
the constraints method is used to retrieve the constraints of a target expression
(with the default implementation returning an empty set), while the remaining
methods serve as utilities to generate sets of constraints.
Non-Relational Analyses
One of the key objectives of LiSA is the ease of implementing new analyses by reusing existing components. Non-relational analyses (or more formally, Cartesian abstractions) compute independent values for different program variables, and are able to evaluate an expression to an abstract values by knowing the abstract values of program variables. Both their formalization and their implementation typically relies on (i) a mapping from program variables to abstract values (i.e., lattice instances), and (ii) the ability to recursively evaluate expressions by combining the abstract values of their sub-expressions.
Environments
The mapping from program variables to abstract values is modeled in LiSA through
the Environment class hierarchy:
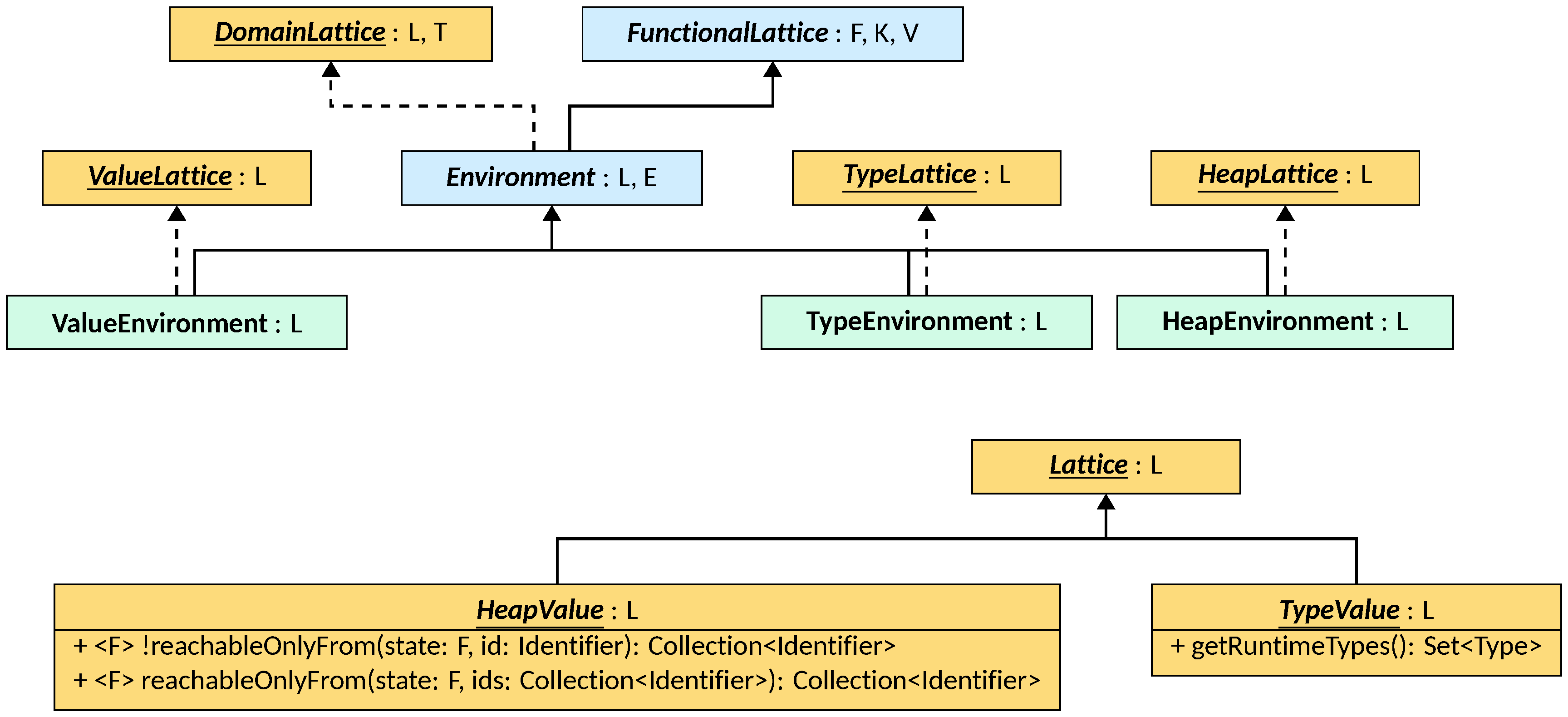
An Environment is a FunctionalLattice that has Identifiers as keys and
lattice instances as values. The class is parametric on the type L, that must
extend Lattice<L>, of the values of the map, and on the concrete type E of
the environment itself, that must extend Environment<L, E>. Environment
extends FunctionalLattice<E, Identifier, L>, meaning that all lattice
operators accept and return values of type E, and implements DomainLattice<E,
E>, meaning that variable and scoping operations also accept and return values
of type E. ValueEnvironment, TypeEnvironment, and HeapEnvironment all
subclass Environment and all possess one type parameter L for the values
they contain (i.e., they all inherit from Environment<L, X<L>>, where X is
ValueEnvironment, TypeEnvironment, or HeapEnvironment respectively).
However, while ValueEnvironment specifies that L can be any lattice instance
(i.e., L extends Lattice<L>), TypeEnvironment and HeapEnvironment restrict
L to be a TypeValue<L> and a HeapValue<L> respectively. These define
additional operations for their specific types:
- since instances of
TypeValueultimately abstract sets of types, the interfaces provides methodgetRuntimeTypesto retrieve such abstraction; HeapValue’sreachableOnlyFrominstead should perform a cut of the memory of the program starting from the givenIdentifiers, returning all thoseIdentifiers that are only reachable from them.
Non Relational Domains
Non-relational domains can be implemented in LiSA by subclassing the
NonRelationalDomain interface:
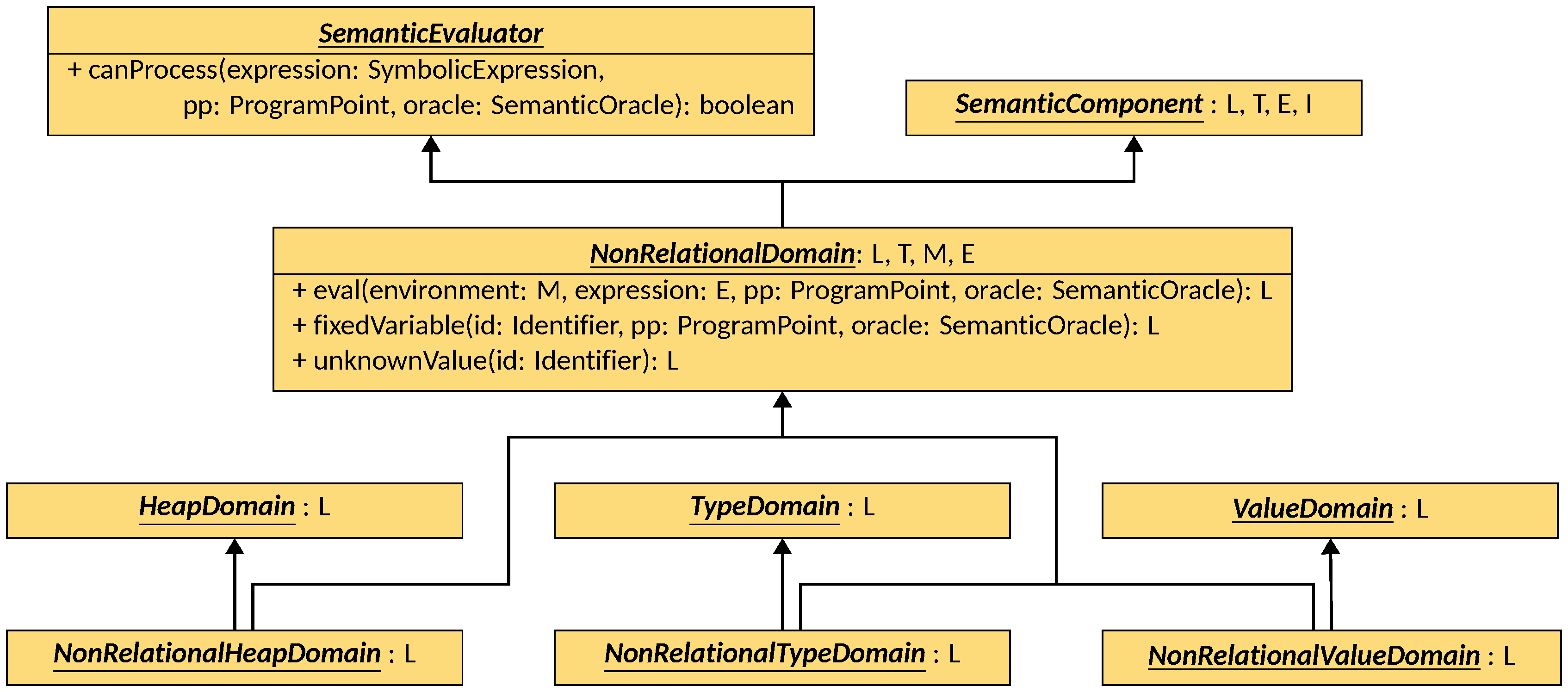
A NonRelationalDomain is parametric on the type L of lattice instances it
uses as values (that must extend Lattice<L>), on the type T of the values it
returns from its transformers, on the type M of the mapping it is designed to
work with (that must extend FunctionalLattice<M, Identifier, L> and DomainLattice<M, T>),
and on the type E of SymbolicExpressions it can process. Note that the binding
allow the type of values used inside the mapping M to differ from the
return type of each tansformer: this is essential for enabling both heap and
value analyses. NonRelationalDomain extends the SemanticComponent<M, T, E, Identifier,
meaning that the domain can be used for all three components (heap, type, and value)
by instantiating M with the corresponding environment type (i.e.,
HeapEnvironment, TypeEnvironment, or ValueEnvironment).
Three methods are defined by the interface:
eval, that given an expression and an environment (i.e., the values of each variable possibly appearing in the expression), evaluates the former to a lattice instance that can be stored in the environment;fixedVariable, that optionally returns a lattice instance that can over-approximate the given variable in all program executions; if this method returns a non-bottom value, all assignments to that variable are ignored, and the variable is always assumed to have that value (this is useful for instance in security analyses, when one wants to assume that certain variables are always under the control of the attacker);unknownValue, that returns a lattice instance to be used when the mappingMis queried for a value that is not present in it.
Three sub-interfaces of NonRelationalDomain are provided to specialize it
for each of the three components:
NonRelationalHeapDomain, parametric in the typeL extends HeapValue<L>of the values to use inHeapEnvironments, that specializesNonRelationalDomainby bindingLtoL,TtoPair<HeapEnvironment<L>, List<HeapReplacement>>,MtoHeapEnvironment<L>andEtoSymbolicExpression, and that also extendsHeapDomain<HeapEnvironment<L>>;NonRelationalHeapDomainis thus aHeapDomainthat mapsIdentifiers toHeapValues through aHeapEnvironment, whose transformers return both a new environment and a substitution, and that can process any symbolic expression;NonRelationalTypeDomain, parametric in the typeL extends TypeValue<L>of the values to use inTypeEnvironments, that specializesNonRelationalDomainby bindingLtoL, bothTandMtoTypeEnvironment<L>andEtoValueExpression, and that also extendsTypeDomain<TypeEnvironment<L>>;NonRelationalTypeDomainis thus aTypeDomainthat mapsIdentifiers toTypeValues through aTypeEnvironment, whose transformers return a new environment, and that can process any value expression;NonRelationalValueDomain, parametric in the typeL extends Lattice<L>of the values to use inValueEnvironments, that specializesNonRelationalDomainby bindingLtoL, bothTandMtoValueEnvironment<L>andEtoValueExpression, and that also extendsValueDomain<ValueEnvironment<L>>;NonRelationalValueDomainis thus aValueDomainthat mapsIdentifiers to lattice instances through aValueEnvironment, whose transformers return a new environment, and that can process any value expression.
Base Implementations
While Environments and NonRelationalDomains provide the necessary infrastructure
for avoiding reimplementation of variable mappings, the recursive expression
evaluation (i.e., the eval method) and the logic for assignments must still be coded from scratch
despite being a process that does not depend on the final implementation.
Recursive evaluation of a symbolic expression can be straightforwardly implemented
using the expressions’ visitor pattern through the ExpressionVisitor interface.
Still, even after the infrastructure has been taken care of, parts of the
implementations can be factored out. In LiSA, this is achieved with the
BaseNonRelationalDomain interface and its children.
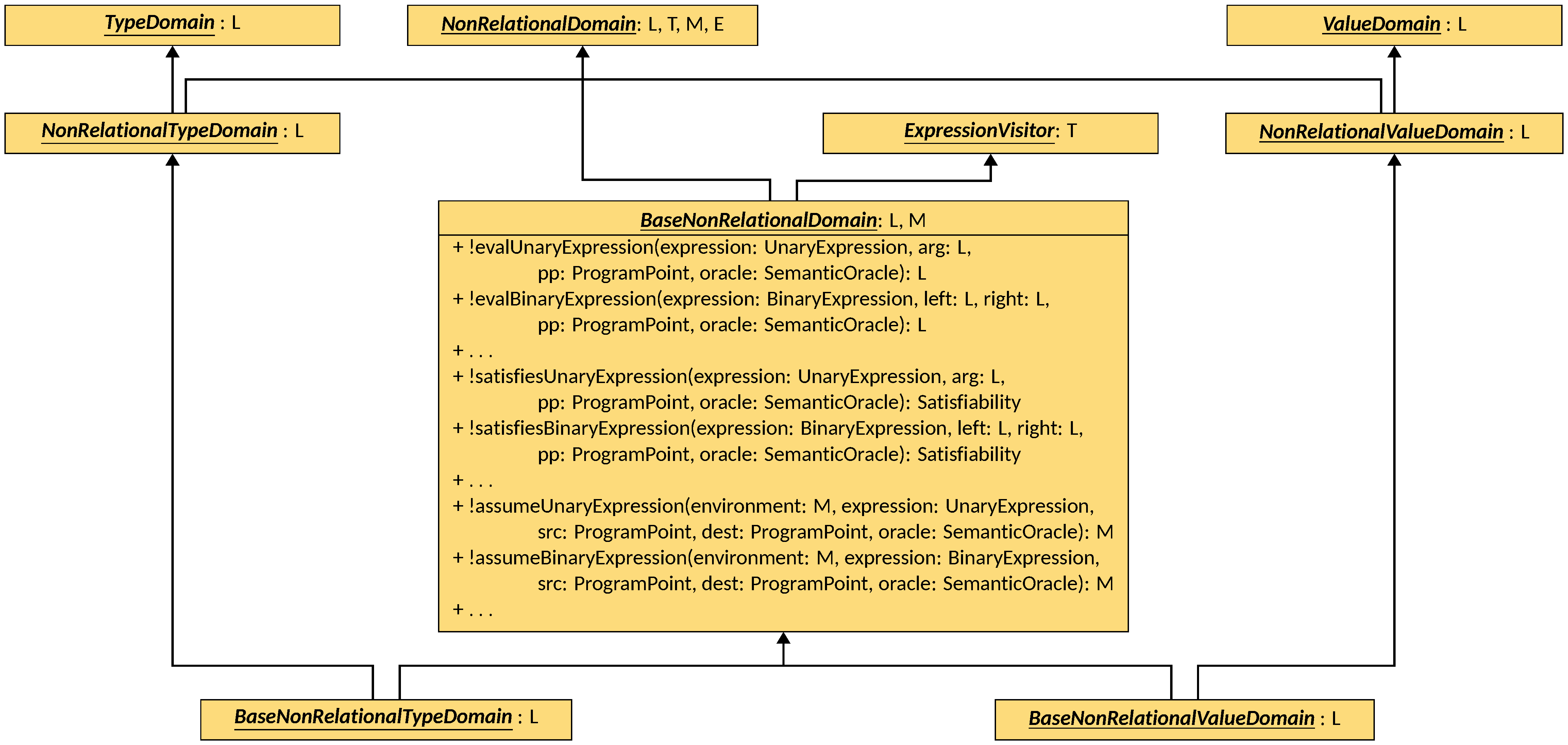
BaseNonRelationalDomain is parametric to the type L, that must extend Lattice<L>,
of the values to use in the mapping, and to the type M of the mapping itself, that must
extend FunctionalLattice<M, Identifier, L> and DomainLattice<M, M>.
The interface extends NonRelationalDomain<L, M, M, ValueExpression>,
meaning that it can process value expressions only, and that its transformers
accept and return instances of M, which in turn maps Identifiers to instances of L.
Additionally, BaseNonRelationalDomain also implements ExpressionVisitor<L>,
meaning that all its visit overloads return instances of L. The interface
provides default implementations for SemanticComponent’s and
NonRelationalDomain’s transformers:
assignevaluates the right-hand side expression througheval, which produces an instance ofL; then, the assignment is performed by both considering the result offixedVariableand the possible weakness of the left-hand side identifier;smallStepSemanticsis a no-op, since variable mappings do not change without assignments;satisfiesevaluates any sub-expression to an instance ofLthrougheval, and then invokes the correspondingsatisfiesXmethod, whereXis the class of the target expression, after automatically handling logical the operatorsand,or, andnot;assumeinvokes the correspondingassumeXmethod, whereXis the class of the target expression, after automatically handling logical the operatorsand,or, andnot;evalcallsaccepton the target expression using the domain itself as visitor, and passing the environment, the program point, and the oracle as additional parameters;fixedVariablereturns the bottom element ofL;unknownValuereturns the top element ofL;canProcessallows the evaluation of all expressions that can assume aValueType(see the Types page for more information) at runtime.
All visit overloads are implemented by either (i) throwing an exception if the
target of the visit is a HeapExpression, since such base implementations
cannot handle them, (ii) returning the bottom element if one of the sub-expressions
recursive evaluations returned bottom, or (iii) invoking the corresponding evalX method,
where X is the class of the expression being visited. All evalX methods
have default implementations that return the top element of L, symbolizing
that those expressions are not handled and thus over-approximated, and reducing
the number of methods one is required to implement when implementing the
interface to only the strictly required ones.
The same holds for all satisfiesX methods, that by default return Satisfiability.UNKNOWN,
and for all assumeX methods, that by default return the input environment.
Following the non-relational
approach, evaluations of Identifiers through evalIdentifier simply return
the contents of the environment for that id.
BaseNonRelationalDomain adds only two new methods that must be implemented by
concrete subclasses: top and bottom, that serve as proxies to retrieve the top
and bottom elements of L, respectively.
BaseNonRelationalDomain is specialized for value and type analyses through
BaseNonRelationalValueDomain and BaseNonRelationalTypeDomain, both
parametric on the type L that must extend Lattice<L> of the values to use in the
mapping. BaseNonRelationalValueDomain extends BaseNonRelationalDomain<L, ValueEnvironment<L>>
and NonRelationalValueDomain<L>, while BaseNonRelationalTypeDomain extends
BaseNonRelationalDomain<L, TypeEnvironment<L>> and NonRelationalTypeDomain<L>.
Both interfaces do not add any new method, but simply bind the type parameters
of BaseNonRelationalDomain to the corresponding environment types.
The
BaseNonRelationalHeapDomain interface is
missing from LiSA as we did not yet find a use case for it. It is however
entirely possible to implement it following the same pattern as the other two
base implementations.
Dataflow Analyses
Following the same idea of non-relational analyses, dataflow analyses also use a shared structure that is independent from the concrete analysis being implemented:
- the domains track sets of elements (that are analysis-specific);
- if the analysis is possible,
lessOrEqualis implemented through subset inclusion,lubis implemented as set union, andglbis implemented as set intersection; otherwise, if the analysis is definite,lessOrEqualis implemented through superset inclusion,lubis implemented as set intersection, andglbis implemented as set union; - the tracked sets are updated using the dataflow formula
F(I) = I \ kill(e, I) U gen(e, I), whereIis the input set of elements,eis the expression being processed, andkillandgenare analysis-specific functions.
This structure is captured by the Dataflow Analysis infrastructure:
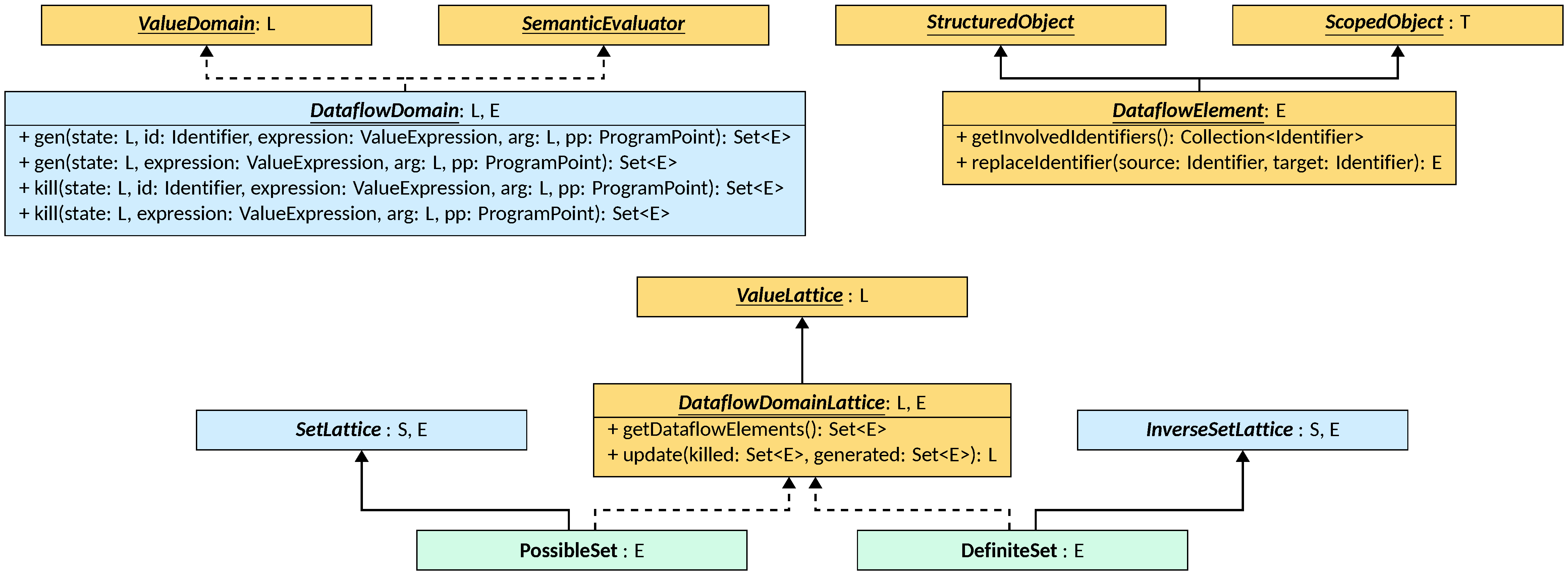
The DataflowDomain interface defines the concrete operations that a dataflow
analysis must support to be used within LiSA. It is parametric to the type L
of DataflowDomainLattice<L, E> to be used (either PossibleSet or
DefiniteSet), and to the type E of DataflowElement<E> that the sets
computed by the domain contain. DataflowDomain is a ValueDomain<L>,
meaning that it can be used in the Simple Abstract Domain
framework as value component producing instances of L. Transformers from
ValueDomain are implemented using the dataflow formula, that in turns use the
implementation-specific gen and kill functions (each with two overloads, one
for assignments and one for non-assigning expressions). Similarly to
BaseNonRelationalDomain, canProcess allows all expressions that have a
ValueType.
A DataflowElement is an object that can be tracked inside the sets produced
by a DataflowDomain. It is parametric to the concrete type E of the element itself,
that must extend DataflowElement<E>, and extends both StructuredObject and
ScopedObject<E>, meaning that it can be converted to a
StructuredRepresentation for dumping and that it supports scoping operations.
DataflowElements typically track symbolic information that refer to
Identifiers: these can be retrieved using the getInvolvedIdentifier method.
Instead, replaceIdentifier produces an element that is identical to the
current one, but where occurrences of source are replaced with target.
Finally, the sets produced by DataflowDomains are modeled through the
DataflowDomainLattice interface, parametric to the concrete type L of the
lattice itself, that must extend DataflowDomainLattice<L, E>, and to the type E of
DataflowElement<E> contained in the sets. These are ValueLattice<L>s where
lattice operations are implemented through set operations (union or intersection,
depending on whether the analysis is possible or definite). The elements
contained in the set can be retrieved through the getDataflowElements method,
and can be updated using the update method. Two concrete instances of this
interface exist:
PossibleSet, parametric on the typeE extends DataflowElement<E>that it contains, that implements a possible dataflow analysis by extendingSetLattice<PossibleSet<E>, E>;DefiniteSet, parametric on the typeE extends DataflowElement<E>that it contains, that implements a possible dataflow analysis by extendingInverseSetLattice<DefiniteSet<E>, E>.
With this infrastructure, one has to simply create a DataflowElement instance
that tracks the information of interest, and then implement a DataflowDomain
that defines the gen and kill functions to specify how such information is
updated when processing each expression. The possible or definite nature of the
analysis follows by the type of DataflowDomainLattice used.