Symbolic Expressions
Symbolic expressions are LiSA’s internal language for defining atomic operations that a program performs during its execution. These are the subjects of the evaluations performed by Semantic Domains to infer program properties, and allow domain definitions that are independent of the source programming language. The rationale behind this design choice is to allow LiSA to support multiple programming languages and paradigms by not attributing any specific meaning to syntactic constructs. For instance, an assignment in Python can automatically wrap or unwrap tuple values, while in Java it can perform boxing or unboxing of primitive types, neither of which happens in C. Thus, LiSA allows Statements (i.e., syntactic constructs appearing in the source program) to implement their own semantics by decomposing themselves into a series of symbolic expressions that capture the intended operations in a language-agnostic way. This allows abstract domains to focus on the semantics of small and well-defined operations, rather than having to deal with the peculiarities of each programming language. The decomposition is semantic: the state of the analysis can be queried for any information (e.g., types of variables, values of constants, aliasing of memory locations) that may be needed to narrow down the possible behaviors of the expression. The same statement can thus produce a different decomposition each time it is analyzed, depending on the current state of the analysis. Symbolic expressions are also extensible, meaning that new ones can be added to support new language constructs or paradigms.
In this page, we present the main interfaces and classes that define symbolic expressions in LiSA, focusing on ones that have an important role in the overall design of the framework.
This page contains class diagrams. Interfaces are represented with yellow rectangles, abstract classes with blue rectangles, and concrete classes with green rectangles. After type names, type parameters are reported, but their bounds are omitted for clarity. Only public members are listed in each type: the
+ symbol marks instance members, the * symbol marks
static members, and a ! in front of the name denotes a member with a default
implementation. Method-specific type parameters are written before the method
name, wrapped in <>. When a class or interface has already been introduced in
an earlier diagram, its inner members are omitted.
The Symbolic Expression Class
The SymbolicExpression class is the root of the symbolic expression hierarchy. It
extends the ScopedObject<SymbolicExpression> interface, meaning that all symbolic expressions
can be scoped when entering or exiting a new context during an analysis.
This is particularly useful for expressions that contain
Identifiers, as it allows to isolate variable references
when analyzing function calls. In the class diagrams in the remainder of this
page, methods have been removed from concrete expression instances for the sake
of clarity, and they will be described in the relevant sections.
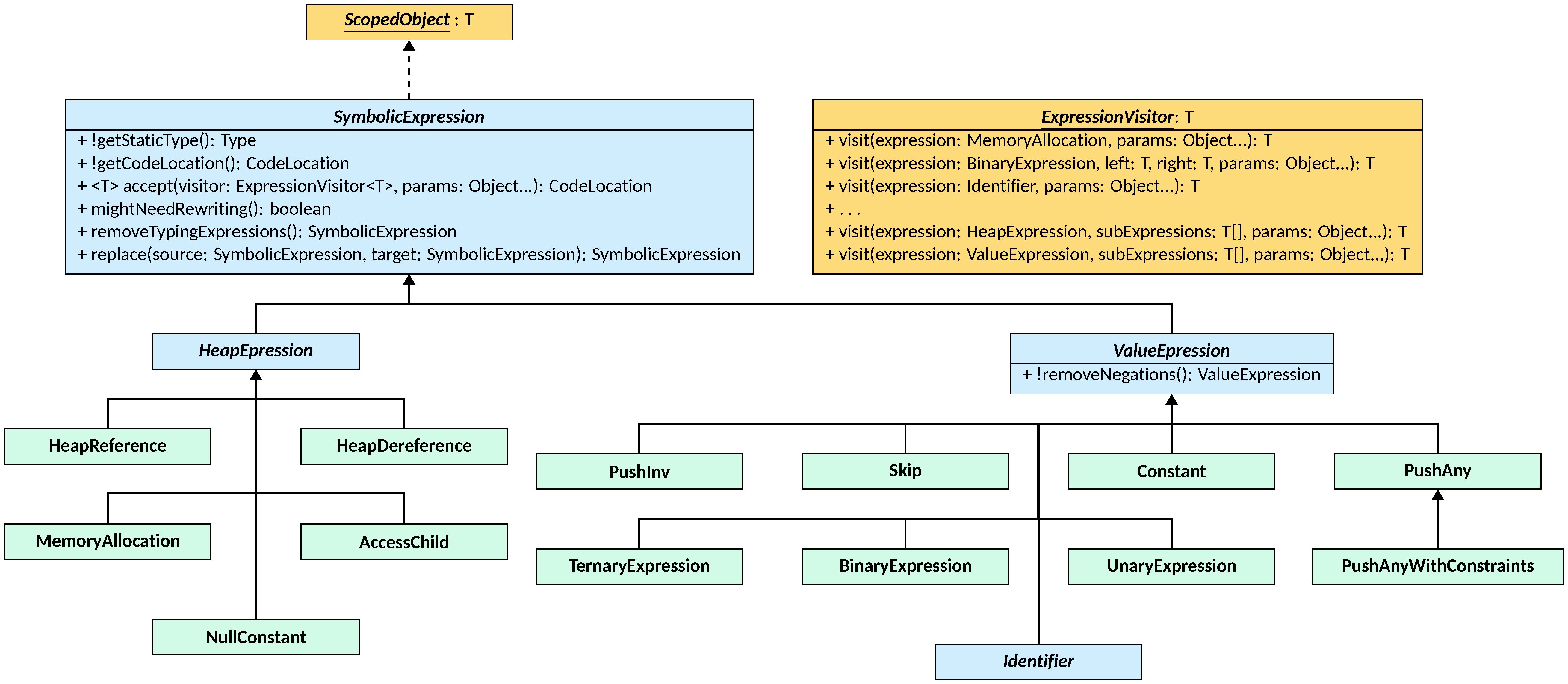
Each symbolic expression is identified by a static Type,
that is, a supertype of all possible runtime types the expression can take, and
a Code Location,
corresponding to the syntactic construct that generated the expression. SymbolicExpression
defines three abstract methods that must be implemented by all subclasses:
mightNeedRewriting, that returnstrueif the expression may need to be rewritten by an analysis before being evaluated byValueDomains when using the Simple Abstract Domain framework;removeTypingExpressions, that returns a copy of the expression where all type conversions and casts have been removed, simplifying the expression for inspection by components that do not need type information;replace, that returns a copy of the expression where all occurrences of a given sub-expression have been replaced by another expression; this is useful for analyses that need to substitute parts of an expression.
Other than the above methods, SymbolicExpression instances must define accept,
which plays a central role in LiSA as it allows recursive traversal of symbolic
expressions through the visitor pattern. When a recursive traversal is needed,
one can simply call accept on the root expression, passing an
ExpressionVisitor to it together with any additional parameters needed. The
ExpressionVisitor interface is parametric on the type T of the value
returned by each visit operation. The interface defines a visit method for
each concrete subclass of SymbolicExpression, allowing to define custom
behaviors for each expression type. It also defines visits for arbitrary
HeapExpressions and ValueExpressions, that can be used to cover user-defined
expressions not bundled within LiSA. The recursive traversal happens
automatically: each visit method receives as parameter the expression being
visited, the result of recursive visits on its sub-expressions, and any
additional parameters passed to the initial accept call. SymbolicExpression
define accept by simply calling the appropriate visit method on the
visitor, passing itself and the results of recursive accept calls on its
sub-expressions.
The SymbolicExpression class hierarchy is split among HeapExpressions, that
represent operations that manipulate the dynamic memory (e.g., object creation,
field access), and ValueExpressions, that represent operations that produce
values (e.g., arithmetic operations, constants). This distinction is important
as it allows analyses to focus on either heap manipulations or value computations,
depending on their purpose. Both kinds of expressions can be combined to form
complex expressions that manipulate both values and memory locations.
Heap Expressions
Heap expressions are symbolic expressions that represent operations that manipulate the dynamic memory of the program. These include:
MemoryAllocation, that allocates a new region of memory for a new object, array, or other data structure; the allocation can happen on the heap or on the stack, and can be provided with a set of Annotations that give additional information about the allocation itself;HeapReference, that creates a reference to a memory location identified by an innerSymbolicExpression;HeapDereference, that accesses the memory location pointed to by an innerSymbolicExpression;AccessChild, that accesses a child location (e.g., a field of an object, an element of an array) of a memory location, where both thechildand thecontainerare represented by innerSymbolicExpressions;NullConstant, that represents thenull(orNone,nil, etc.) value in the program.
When adopting the Simple Abstract Domain framework,
heap expressions are always rewritten by the HeapDomain before being
evaluated by ValueDomain and TypeDomain.
Value Expressions
Value expressions are symbolic expressions that represent operations
that produce values during program execution. ValueExpressions offer an
additional method: removeNegations, that simplifies boolean expressions by
removing negations and inverting comparison operators, where possible.
Value expressions include:
Constant, that represents a constant value of any type in the program;Skip, that represents a no-operation expression that produces no value;PushInv, short for push invalid value, that represents an expression that pushes an invalid value onto the evaluation stack, that should be interpreted as a bottom value by analyses;PushAny, short for push any value, that represents an expression that pushes an unknown value onto the evaluation stack, that should be interpreted as a top value by analyses;PushAnyWithConstaints, a version ofPushAnyenriched with arbitrary binary constraints (i.e.,BinaryExpressions with comparison operators) that the unknown value must satisfy;UnaryExpression,BinaryExpression, andTernaryExpression, that represent unary, binary, and ternary operations on innerSymbolicExpressions, respectively; these classes are parametric on the operator type, which is represented by a user-defined object;Identifier, that represents a named location (either a real program variable or a synthetic one used by the analysis to track some special value) in the program.
When adopting the Simple Abstract Domain framework,
value expressions might be rewritten by the HeapDomain before being
evaluated by ValueDomain and TypeDomain. This is because sub-expressions of
a value expression may be heap expressions that need to be rewritten first.
Identifiers
Identifiers play a key role in LiSA: other than modeling program variables,
they are also used by a number of analysis components to represent special
values (e.g., the return value of a function, the exception being thrown).
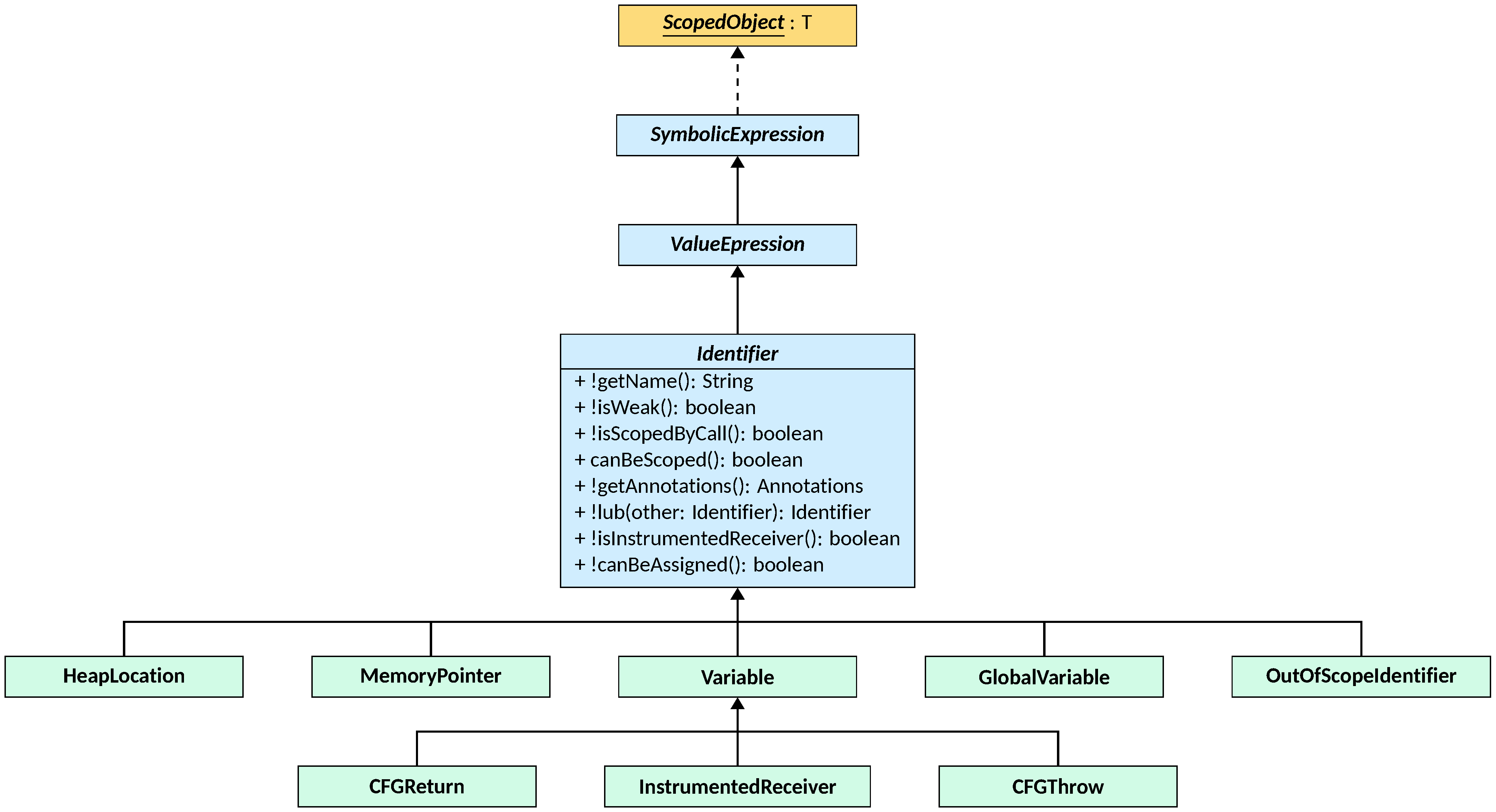
An Identifier is a ValueExpression that is uniquely identified by its name.
An identifier can be weak (as returned by the isWeak method), meaning that it
can represent multiple memory locations at once (e.g., when modeling aliasing
or arrays) or strong, meaning that it represents a single program variable.
As discussed in
the Semantic Domain page,
special care must be taken when updating weak identifiers to avoid unsound
behaviors.
Identifiers can also be scoped, meaning that they can be hidden behind some
program construct (e.g., function calls) to avoid clashing with local
definitions. For instance, when an Identifier named x is scoped by the
instruction scope, it undergoes a sort of renaming, becoming [scope]x. This allows
to distinguish between different instances of x defined in different scopes.
Method canBeScoped returns true if the identifier can be scoped, while
isScopedByCall returns true if the identifier has been scoped by a call.
An identifier can be combined with another one through lub, that raises an
exception whenever the two identifiers are not compatible (i.e., they have different
names). If they have the same name, the resulting identifier is weak if at least one of
the two is weak.
Two more predicates are provided by the Identifier class: canBeAssigned,
returning whether assignments having that identifier as left-hand side are allowed
(useful for preventing assignments to special memory locations), and
isInstrumentedReceiver, returning true if the identifier represents an
entity (e.g., object or array) that is being initialized by the current
expression.
Identifier has five direct subclasses:
Variables represent program or synthetic variables and are always strong;HeapLocations represent memory locations allocated during program execution and can be either weak or strong but cannot be scoped;GlobalVariablesrepresent global program variables (or class static variables), are always strong, and cannot be scoped;MemoryPointers represent references toHeapLocations, are always strong, and cannot be scoped;OutOfScopeIdentifiers are identifiers that have been created by scoping another one (including anotherOutOfScopeIdentifier), that maintain the weakness property of the original identifier and can be scoped again.
Thus, any identifier that can be scoped becomes an OutOfScopeIdentifier named
scope:name, where scope is the ScopeToken (see the definition of the
Scoped Object Interface)
used to scope it, and name is the original identifier’s name.
Finally, the Variable class has three subclasses representing special
synthetic variables that LiSA uses to model specific program constructs:
InstrumentedReceivermodels the entity (e.g., object or array) being initialized by the current instruction;CFGReturnstores the value returned byreturnstatements in control flow graphs;CFGThrowstores the exception being thrown bythrowstatements in control flow graphs.
Finally, all Identifiers carry a set of
Annotations that
can be used to model metadata on the variable or locations it represent.
Annotations can obtained directly from the code (e.g., by parsing Java
annotations, Python type hints, C# attributes, etc.) or by propagation:
for instance, when a call to a function, method, or procedure f is analyzed, all annotations
on the return value of f are propagated to the CFGReturn variable
representing the return value of the call. This propagation can be useful for
implementing analyses parametric to annotations. An example of this is a taint
analysis that uses annotations to detect tainted values: when a function call
can generate a tainted value, it can be annotated (manually or automatically)
with an analysis-defined annotation (e.g., @Tainted) that will be propagated
to the CFGReturn variable. When determining the taintedness of an Identifier, an
AbstractDomain can inspect its annotations first: if the variable is
annotated, then it is always considered tainted; otherwise, the domain will have
to compute its taintedness based on the values it has been assigned.