Statements, Expressions, and Edges
A statement is an instruction of the program. Statements represent high-level syntactic constructs that can have arbitrarily complex semantics. A statement that produces a value that can be used by other statements is called an expression. Control flow between statements is defined through the edges that connect them, that might be conditional or unconditional. The combination of statements, expressions, and edges form the basis that LiSA uses to represent the content of functions, methods, and procedures.
This page contains class diagrams. Interfaces are represented with yellow rectangles, abstract classes with blue rectangles, and concrete classes with green rectangles. After type names, type parameters are reported, but their bounds are omitted for clarity. Only public members are listed in each type: the
+ symbol marks instance members, the * symbol marks
static members, and a ! in front of the name denotes a member with a default
implementation. Method-specific type parameters are written before the method
name, wrapped in <>. When a class or interface has already been introduced in
an earlier diagram, its inner members are omitted.
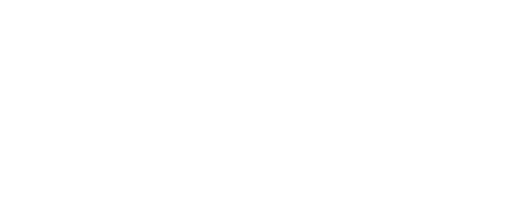
The Statement class
A Statement implementation corresponds to an instruction that can appear in
the program. A Statement is both a ProgramPoint (and thus has a
CodeLocation, and is contained in a CFG that is part of a Unit — more on
this two structures can be found in their respective documentation pages) and a
CodeNode (intuitively, a node of a Graph that can be compared to other nodes
with their natural ordering, and that can be visited by a GraphVisitor —
more on CodeNode and GraphVisitor can be found in the CFG documentation
page).
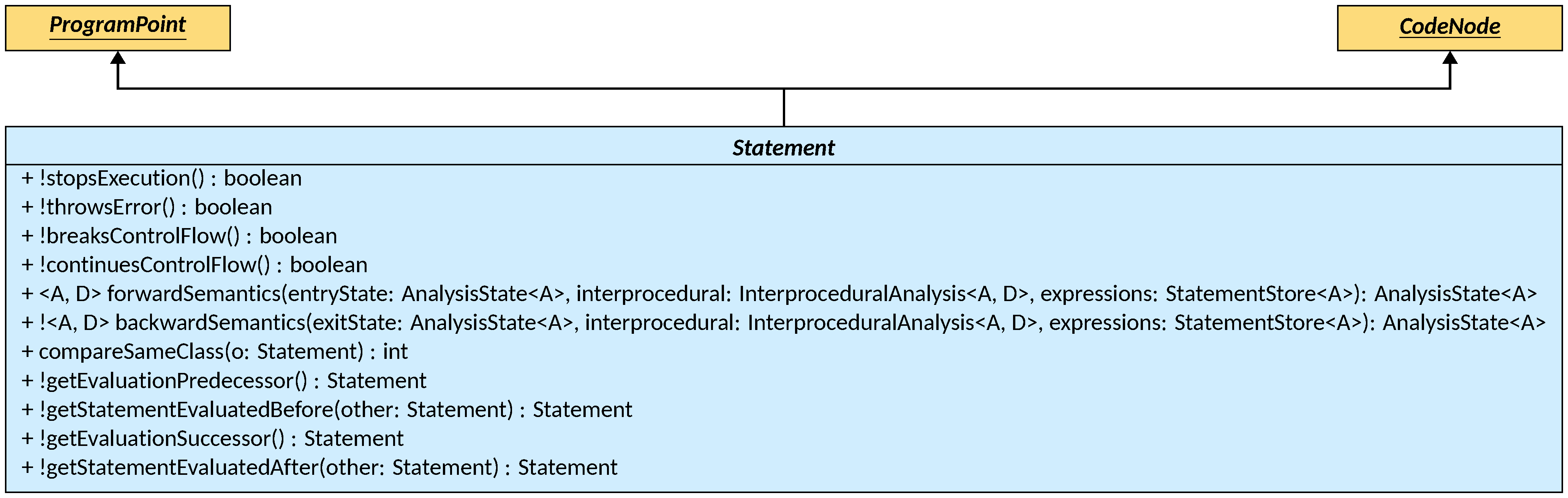
Most methods defined in the Statement class are used to determine syntactic
features of it and to navigate related statements. Specifically, a Statement
might stop the execution of the function, method or procedure it belongs to
(e.g., a return statement, a throw statement, or a call to an exit
function that halts the program): these are identified by stopsExecution()
implementations that return true (the default implementation of this method
yields false). To further distinguish between normal and erroneous stopping,
the throwsError() method identifies statements that stop the execution by
raising an error (e.g., a throw statement, but not a return statement), with
its default implementation returning false. For control-flow altering
statements, the breaksControlFlow() and continuesControlFlow() methods
identify statements that interrupt one or more enclosing loops (e.g., a break
statement) or that cause the jump to the next iteration of one or more enclosing
loops (e.g., a continue statement), respectively, with both default
implementations returning false.
Instead, getEvaluationPredecessor(), getEvaluationSuccessor(),
getStatementEvaluatedBefore(), and getStatementEvaluatedAfter() offer
ways to navigate compound statements, that is, statements that can contain other
statements. In fact, a statement does not need to be atomic: in can be
recursively defined as the application of some operation to one or more inner
statements, that take the name of expressions and that are detailed in the
next section. Intuitively, an expression is a statement that produces a value,
and such value can either be discarded if unused (e.g., if x + 1 lives on its
own line without being assigned to a value), or used in enclosing expressions or
statements to compute further results. It follows that an expression can be
compound as well, as in x + (3 / y). With compound statements and expressions,
it can be useful to understand what other instruction is executed before or
after the current one in the context of the current outer-most statement. The
four methods above serve this purpose: getEvaluationPredecessor() and
getEvaluationSuccessor() yield the statement or expression that is executed
immediately before and after the current one, respectively, limiting the search
to the current outer-most statement. These return null if the current
statement or expression is the first and last one being executed, respectively.
Similarly, getStatementEvaluatedBefore() and getStatementEvaluatedAfter()
apply the same reasoning on the statement received as parameter, assuming that
it is nested into the current statement or expression. All these methods have
default implementation exploiting the structure of the statement to perform the
search.
The natural order provided by the compareTo method needs to take into account
statement-specific structure. However, parts of the check can be factored out
into a common logic (e.g., the comparison of the CodeLocation of the
statement). The compareTo implementation provided by the Statement class
factors out all common parts of the implementation, and delegates to
compareSameClass for comparing implementation-specific structure.
Implementations of this method can assume that the parameter of the method is of
the same concrete type as the object receiving the call.
Finally, the forward and backward semantics of each statement can be specified
as small step semantics in the forwardSemantics and backwardSemantics
methods, that are covered in the
instruction semantics page.
Implementing compound statements
A common theme in LiSA is to factor out common aspects of the various
implementations. When implementing compound statements, most parts of the
implementation can be factored out: the recursive nature of visiting operations,
semantics computations, and even comparison operation is independent of the
actual statement being implemented. The NaryStatement and its subclasses are
designed to take care of this factorization.
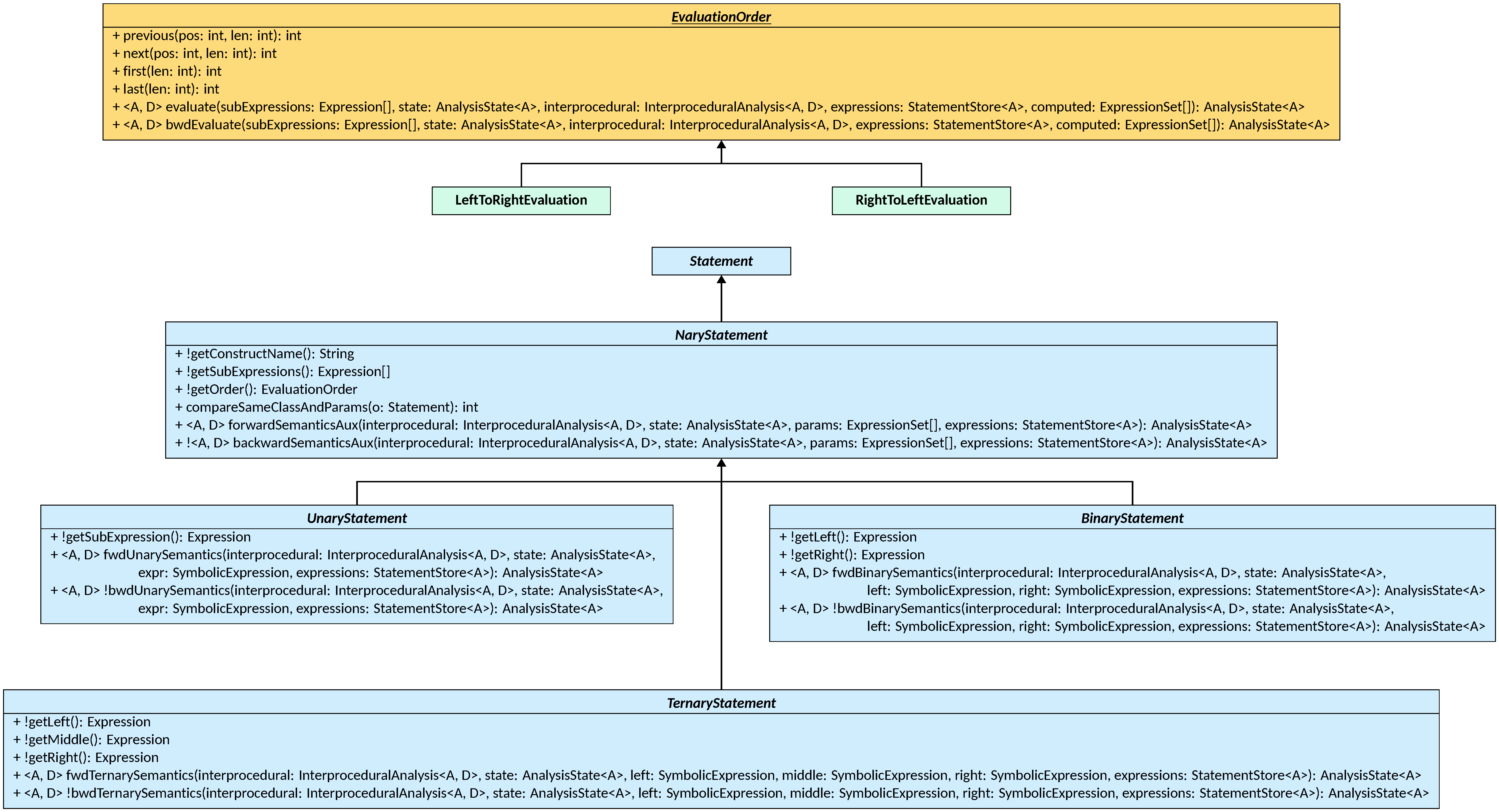
The NaryStatement class is a Statement that contains an array of nested
expressions, accessible through the getSubExpressions() method.
The name of the statement, intended as a string to use when
converting the statement to a string, is provided at construction and accessible
through the getConstructName() method. Following the same reasoning of the
Statement class, compareSameClass is implemented by comparing the construct
name and all of the sub-expressions first, such that the only remaining task is
to compare implementation-specific fields defined in child classes through the
compareSameClassAndParams() method. Semantics computations also follow a
common structure: for forward semantics, the semantics of the current statement
is computed after the semantics of each sub-expression is computed, chaining the
computations on the intermediate states generated. The order of the sub-expressions
evaluations is defined by the EvaluationOrder implementation passed at
construction, that is responsible for chaining the evaluations and storing the
result of each of them in the provided StatementStore. Once the
EvaluationOrder returns, the implementation-specific semantics is delegated to
the forwardSemanticsAux method, that can access all of the
SymbolicExpressions computed for each sub-expression and evaluate them to
obtain the final state. A similar reasoning is applied in the backward semantics.
The computations of forwardSemanticsAux can be factored out as well: all
implementations will loop over the sub-expressions’ computed expressions,
with as many nested loops as the maximum number of sub-expressions. For the
three most common cases of one, two, and three sub-expressions, the NaryStatement
is subclassed by UnaryStatement, BinaryStatement, and TernaryStatement, that
implement the necessary number of nested loops in forwardSemanticsAux and
delegate the actual semantics computations on each combination of symbolic
expressions to fwdUnarySemantics, fwdBinarySemantics, and
fwdTernarySemantics, respectively. The three subclasses also provide utility
methods to access the sub-expressions.
The
Statement class should be subclassed only to
create statements that are not compound. For compound statements, it is
advised to subclass one of the NaryStatement subclasses, depending on the number of
sub-expressions, or the NaryStatement class directly if the number of
sub-expressions exceeds three. This ensures the usage of well-tested logic, and
also guarantees that all methods that should be called for infrastructural
reasons are correctly invoked.
The Expression class
An Expression is a Statement that produces a value that can be used by other
statements:
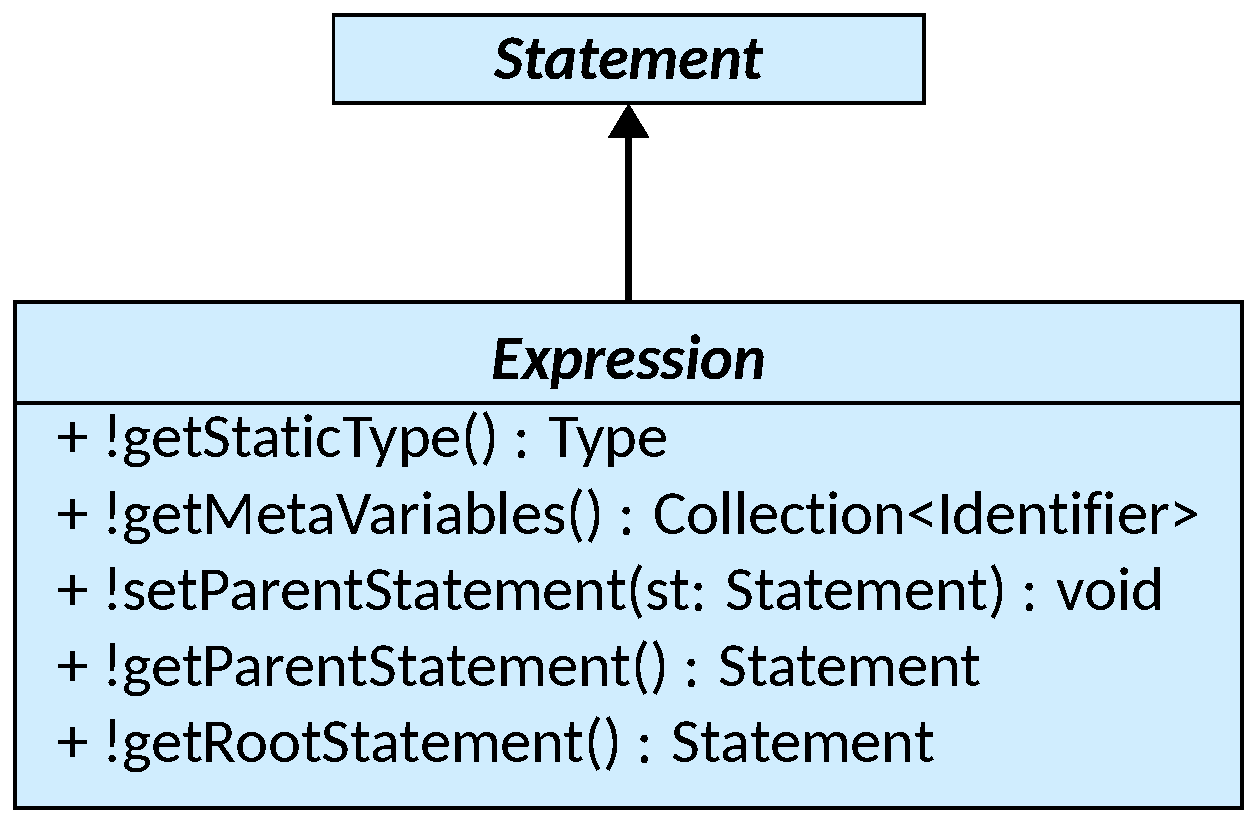
An Expression adds to the Statement class few methods to reflect both the
value produced and the relation to the containing statement or expression, if
any. The getStaticType() method returns the static type of the value produced
by the expression, that is, a type which is an upper bound of the types of all
possible values that the expression can produce at runtime. Instead, three
methods exist to navigate the syntactic structure of an expression w.r.t. it’s
container: getParentStatement() yields the inner-most statement (or
expression) that contains the current one, if any, while getRootStatement()
returns the outer-most statement that contains the current one, if any. Note
that if the current expression is not contained in any statement but is instead
a complete instruction (e.g., if x + 1 lives on its own line without being
assigned to a value), getParentStatement() yields null while
getRootStatement() returns the expression itself. To record a
container-contained relationship, setParentStatement() can be called on the
contained expression by passing the container expression as parameter.
NaryStatement and NaryExpression (detailed in
the next section) invoke setParentStatement() automatically.
Meta variables
For some expressions, it can be useful to store either partial results or the
final result of the semantic computation in instrumented variables. These do not
correspond to real program variables, and their values should be forgotten as
soon as they can no longer be used. One can think of these variables as special
stack elements: as soon as the root statement has completed its execution, they
become inaccessible to the rest of the program (ignoring arbitrary pointer
arithmetics that can still retrieve them), and can thus be forgotten. These are
modeled in LiSA with meta variables. Implementations of expression semantics
can assign values to Identifiers that correspond to instrumented variables,
and add them to the collection of meta variables with
getMetaVariables().add(id). These will be propagated to the parent statement’s
meta variables, until they reach the root statement. When the fixpoint algorithm
leaves the root statement to analyze its successors, it will call
state.forgetIdentifiers(root.getMetaVariables()) on the state resulting from
the root’s semantics to remove them. Example usages of meta variables in LiSA
are:
- storing the result of a
Callthat returned something, as they cannot be modeled with symbolic expressions; - storing the value produced by a
returnstatement, as it could use local variables that are no longer in scope when the value is propagated to the caller and needs to be evaluated; - holding a reference to a newly allocated object or array to use during initialization, before it is assigned to a value.
Implementing compound expressions
Following the same reasoning of the NaryStatement class, LiSA also provides
the NaryExpression class and its subtypes:
The NaryExpression class is an Expression that contains an array of nested
expressions, accessible through the getSubExpressions() method.
The name of the statement, intended as a string to use when
converting the statement to a string, is provided at construction and accessible
through the getConstructName() method. Following the same reasoning of the
Statement class, compareSameClass is implemented by comparing the construct
name and all of the sub-expressions first, such that the only remaining task is
to compare implementation-specific fields defined in child classes through the
compareSameClassAndParams() method. Semantics computations also follow a
common structure: for forward semantics, the semantics of the current statement
is computed after the semantics of each sub-expression is computed, chaining the
computations on the intermediate states generated. The order of the sub-expressions
evaluations is defined by the EvaluationOrder implementation passed at
construction, that is responsible for chaining the evaluations and storing the
result of each of them in the provided StatementStore. Once the
EvaluationOrder returns, the implementation-specific semantics is delegated to
the forwardSemanticsAux method, that can access all of the
SymbolicExpressions computed for each sub-expression and evaluate them to
obtain the final state. A similar reasoning is applied in the backward semantics.
The computations of forwardSemanticsAux can be factored out as well: all
implementations will loop over the sub-expressions’ computed expressions,
with as many nested loops as the maximum number of sub-expressions. For the
three most common cases of one, two, and three sub-expressions, the NaryStatement
is subclassed by UnaryExpression, BinaryExpression, and TernaryExpression, that
implement the necessary number of nested loops in forwardSemanticsAux and
delegate the actual semantics computations on each combination of symbolic
expressions to fwdUnarySemantics, fwdBinarySemantics, and
fwdTernarySemantics, respectively. The three subclasses also provide utility
methods to access the sub-expressions.
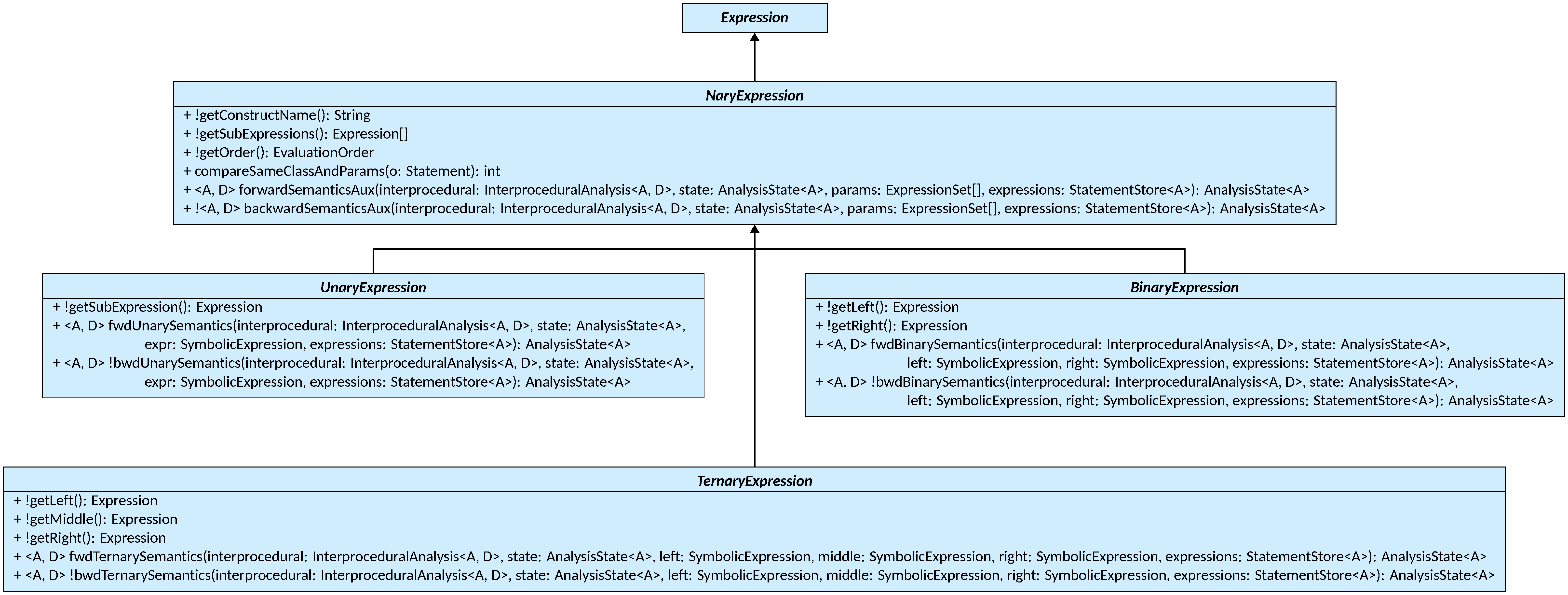
The
Expression class should be subclassed only to
create expressions that are not compound. For compound expressions, it is
advised to subclass one of the NaryExpression subclasses, depending on the number of
sub-expressions, or the NaryExpression class directly if the number of
sub-expressions exceeds three. This ensures the usage of well-tested logic, and
also guarantees that all methods that should be called for infrastructural
reasons are correctly invoked.
The Edge class
Edges connect statements to define the control flow of the program. An Edge
is an instance of CodeEdge (intuitively, an edge of a Graph that can be
compared to other edges with their natural ordering, and that can be visited by
a GraphVisitor — more on CodeEdge and GraphVisitor can be found in the
CFG documentation page).
Additionally, CodeEdge defines three methods that all Edge implementations
provide: isUnconditional(), reporting if the edge is always traversed or if it
relies on some condition, isErrorHandling(), identifying edges that are only
traversed to handle errors or exceptions, and newInstance, that allows to
create a copy of an edge with the same type and properties but different
endpoints.
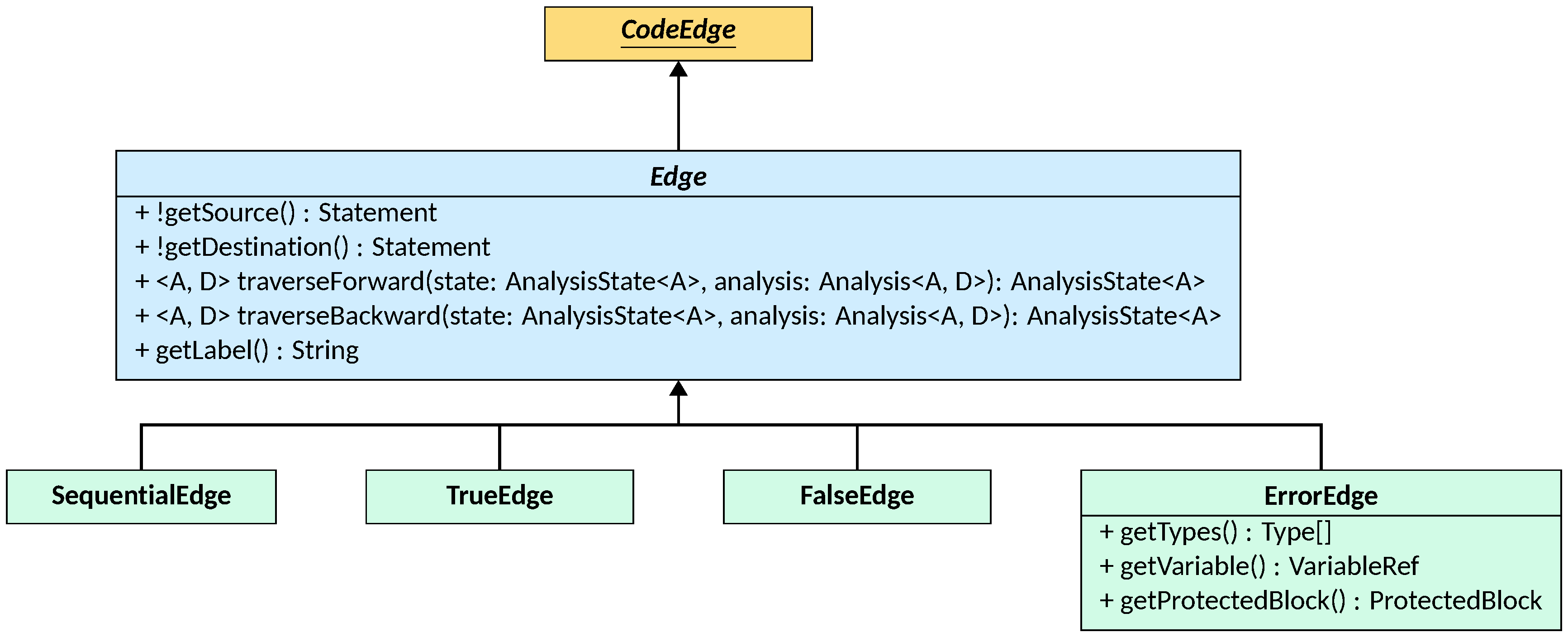
The Edge class stores the endpoints of the edge, and an optional label,
returned by getLabel(), to visually distinguish different edges of the same
kind between the same endpoints.
Four Edge instances are provided by LiSA:
SequentialEdge, modeling the unconditional flow from a statement to the next one;TrueEdge, modeling the conditional flow from a statement to the next one when the condition defined by the source statement holds;FalseEdge, modeling the conditional flow from a statement to the next one when the condition defined by the source statement does not hold;ErrorEdge, modeling the flow from a statement to the next one when the source is in a protected execution block (e.g., atryblock in Java), and the destination is in the corresponding error handling block (e.g., thecatchblock in Java); this edge is traversed when an error whose type is in the ones returned by the edge’sgetTypes()method is raised inside the block of code it protects (more information on protection blocks is available in the control flow graphs documentation).
All edge instances define two traverse methods, one for forward and one for
backward traversal, that transform the post-state of the source statement into the
pre-state of the destination statement. Specifically, sequential edges do not modify
the state, while true and false edges use the assume transformer to refine the
domain with the (negated) condition defined by the source statement. Error edges
instead filter the errors and smashed errors defined in the state according to
the block they protect and the types they handle: if any is found, the least
upper bound of the corresponding states overwrites the normal executions state,
the errors are removed, and the resulting state is propagated to the destination statement.