Annotations
This page contains class diagrams. Interfaces are represented with yellow rectangles, abstract classes with blue rectangles, and concrete classes with green rectangles. After type names, type parameters are reported, but their bounds are omitted for clarity. Only public members are listed in each type: the
+ symbol marks instance members, the * symbol marks
static members, and a ! in front of the name denotes a member with a default
implementation. Method-specific type parameters are written before the method
name, wrapped in <>. When a class or interface has already been introduced in
an earlier diagram, its inner members are omitted.
Annotations are a powerful mechanism for attaching metadata to various program elements. Annotations can either be parsed directly from the source code or be generated at parsing time, exploiting some definition in the static analyzer.
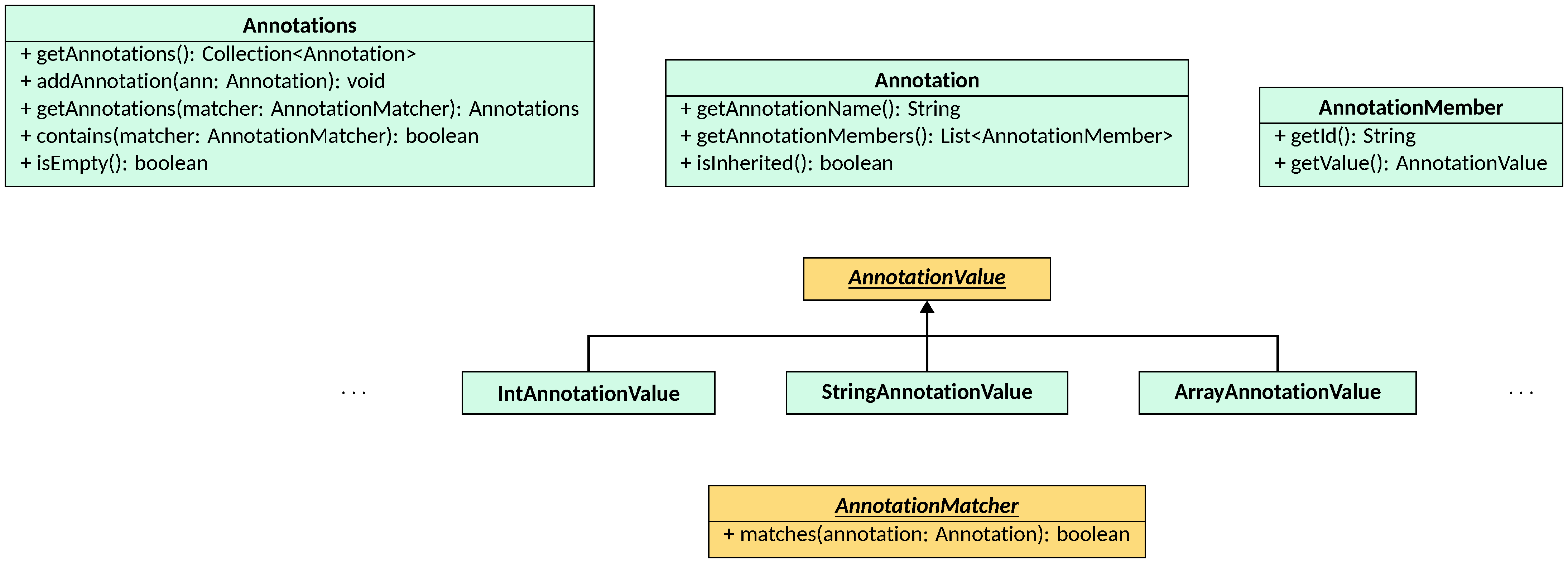
An Annotation consists of a name and a list of members, that are key-value
pairs. The AnnotationValue class forces a natural order among the different
types of values, so that they can be easily compared and sorted. A number of
instances of this interface exist, one for each type of value that can be used
(i.e., boolean, byte, char, double, float, int, long, short, string, class —
identified by the name of the class —, enum — identified by the name of the
enum and the name of the field —, annotation, array).
Sets of annotations can be created using the Annotations class, that contains
a collection of Annotation instances and that provides utilities for searching
for annotations. To allow for annotations being added after the parsing phase by
e.g. applying some summaries of the libraries used by the program, the
Annotations class is mutable through the addAnnotation method.
Modifications to the annotations of a program element should happen with care,
and only before the analysis starts.
Searching for Annotations
Annotations can be attached to several program elements in LiSA. Specifically,
Annotations instances are carried by:
CompilationUnitinstances (classes, interfaces, …) viagetAnnotations();CodeMemberDescriptorinstances (one for eachCFGorNativeCFG) viagetAnnotations()andgetAnnotationsOf(String, Statement)for local variables;Parameterinstances (formal parameters of code members) viagetAnnotations();Globalinstances (global variables and fields) viagetAnnotations().
Additionally, Identifier instances in Symbolic Expressions carry annotations as well, so that
annotation information is accessible during the analysis when evaluating
expressions. These model both annotations on program variables themselves
(i.e., present in the source code or generated by the parsing process) and
annotations obtained through propagation. For instance, when a call to a
function, method, or procedure f is analyzed, all annotations on the return
value of f are propagated to the CFGReturn variable representing the return
value of the call. This propagation can be useful for implementing analyses
parametric to annotations. An example of this is a taint analysis that uses
annotations to detect tainted values: when a function call can generate a
tainted value, it can be annotated (manually or automatically) with an
analysis-defined annotation (e.g., @Tainted) that will be propagated to the
CFGReturn variable. When determining the taintedness of an Identifier, an
AbstractDomain can inspect its annotations first: if the variable is
annotated, then it is always considered tainted; otherwise, the domain will
have to compute its taintedness based on the values it has been assigned.
Searching within an Annotations instance is done through the AnnotationMatcher
interface, whose single method matches(Annotation)
returns true if the given annotation matches. The main provided implementation
is BasicAnnotationMatcher, which matches annotations by name. Custom matchers
can be defined either by implementing the interface or by passing a lambda.
Given an AnnotationMatcher, the Annotations class provides two lookup
methods:
contains(AnnotationMatcher), that returnstrueif at least one annotation in the collection matches the given matcher;getAnnotations(AnnotationMatcher), that returns a newAnnotationsinstance containing only the annotations that match the given matcher.
The isEmpty() method can be used to quickly check whether a collection
contains no annotations at all, which is a common fast path in analysis code.
Annotation Propagation
Annotations are propagated during program validation, which takes place before the analysis starts (see the Language Features page). The propagation follows two distinct axes: the class hierarchy and the override chain.
Hierarchy propagation. When a CompilationUnit is validated, the
annotations defined on each of its ancestor units are propagated to it. This
means that if a class B extends a class A, and A carries some annotations,
those annotations will also appear on B after validation. Propagation is
transitive and covers the entire ancestry chain.
Override chain propagation. When a code member overrides another (e.g., a
method in a subclass overrides one in a superclass), the annotations of the
overridden code member are propagated to the overriding one. The same happens
for the corresponding formal parameters: annotations on the i-th parameter of
the overridden method are propagated to the i-th parameter of the overriding
one.
Whether an annotation participates in propagation is controlled by the
isInherited() flag of the Annotation class. Annotations where
isInherited() returns true are propagated along both axes; those where it
returns false (the default) are not. This allows frontends to mark some
annotations as local to the element they are attached to.
In addition to hierarchy-level propagation, LiSA propagates annotations at the
call level during the analysis. When a CFGCall is resolved, the annotations
attached to the descriptor of each target CFG are copied onto the
metavariable that represents the call’s return value. This makes it possible for
an analysis to inspect, at a call site, the annotations that were placed on the
called functions.
Annotation propagation happens during validation (except for descriptor-to-return propagation), before the analysis starts. Any annotation added to a program element after validation will not be automatically propagated. Annotations added before validation, however, will participate in propagation as normal.
Customizing the Analysis with Annotations
The most common use of annotations in LiSA is to let users of a static analyzer attach semantic metadata to program elements, which an analysis then reads to refine its abstractions. A typical pattern is the following:
- define one or more
Annotationconstants representing the annotations the analysis understands, identified by a unique name (e.g.,"lisa.taint.Tainted"); - define the corresponding
AnnotationMatcherconstants (e.g., usingBasicAnnotationMatcher) that will be used to probeAnnotationsinstances; - in the analysis, read the annotations of the relevant program elements and use them to compute or refine abstract values.
An example of this is a simple taint propagation analysis, where the return
value of some CFG must always be considered tainted, thus acting as a source
of tainted information. In non-relational value
domains (i.e., implementations of BaseNonRelationalDomain), the natural entry
point for annotation-driven customization is the fixedVariable method. This
method is called during assignment whenever the analysis needs a fixed abstract
approximation for a given Identifier, and it takes precedence over the
normally computed value when it does not return the bottom element. By
inspecting the annotations of the identifier inside fixedVariable, a domain
can immediately assign a specific abstract value to a variable based on its
annotations, without looking at its computed value. Since a CFG’s return
value is always annotated with the annotations of that CFG, the CFGReturn
identifier will contain a taint annotation whenever a source of tainted data is
invoked. Then, fixedVariable can return a lattice element representing a
tainted value whenever the CFGReturn variable is annotated with the taint
annotation, thus ensuring that the taint is correctly propagated through the
analysis.
For example, the BaseTaint domain of LiSA defines:
public static final Annotation TAINTED_ANNOTATION = new Annotation("lisa.taint.Tainted");
public static final AnnotationMatcher TAINTED_MATCHER = new BasicAnnotationMatcher(TAINTED_ANNOTATION);
and overrides fixedVariable to return a tainted or clean abstract value
depending on which annotations are present on the identifier:
@Override
public L fixedVariable(
Identifier id,
ProgramPoint pp,
SemanticOracle oracle)
throws SemanticException {
Annotations annots = id.getAnnotations();
if (annots.isEmpty())
return bottom();
if (annots.contains(BaseTaint.TAINTED_MATCHER))
return tainted();
return bottom();
}
Annotations on program elements other than identifiers (e.g., on compilation
units or code member descriptors) can be accessed through the Program or the
ProgramPoint, and can be used in any part of the domain’s logic, not just in
fixedVariable.