LiSA’s Structure
This website describes LiSA’s architecture and provides guides on how to use and extend it. It is intended to be valid for the latest stable release of LiSA, but should be compatible with versions 0.2 and later. Signatures or packages might differ in older versions, but the overall architecture and design principles should remain the same.
The documentation is still under construction: some pages are still missing.
This section describes the internal structure of LiSA, providing an overview of its main components and how they interact with each other.
The codebase of LiSA is split into four projects: lisa-sdk, lisa-analyses,
lisa-program, and lisa-imp. The lisa-sdk project contains the core
infrastructure of LiSA, including the analysis engine, the control flow graph
representation, and the framework for defining analyses and checks. The
lisa-analyses project implements a collection of ready-to-use analyses that
can be employed out of the box. The lisa-program project provides simple
Statement implementations that can be used for quick prototyping of analyzers
and for reference. Finally, the lisa-imp project contains an implementation of
the IMP language, which is used for testing and demonstration purposes. The
documentation in this section focuses primarily on the lisa-sdk project, as it
forms the foundation of LiSA’s architecture. Documentation on the IMP language
can be found in the IMP section, while a list of
availble analyses is present under
Configuration. For information on how
to build LiSA and build upon it, refer to the
Get Started section.
A high-level overview of LiSA’s structure is shown in the following diagram:
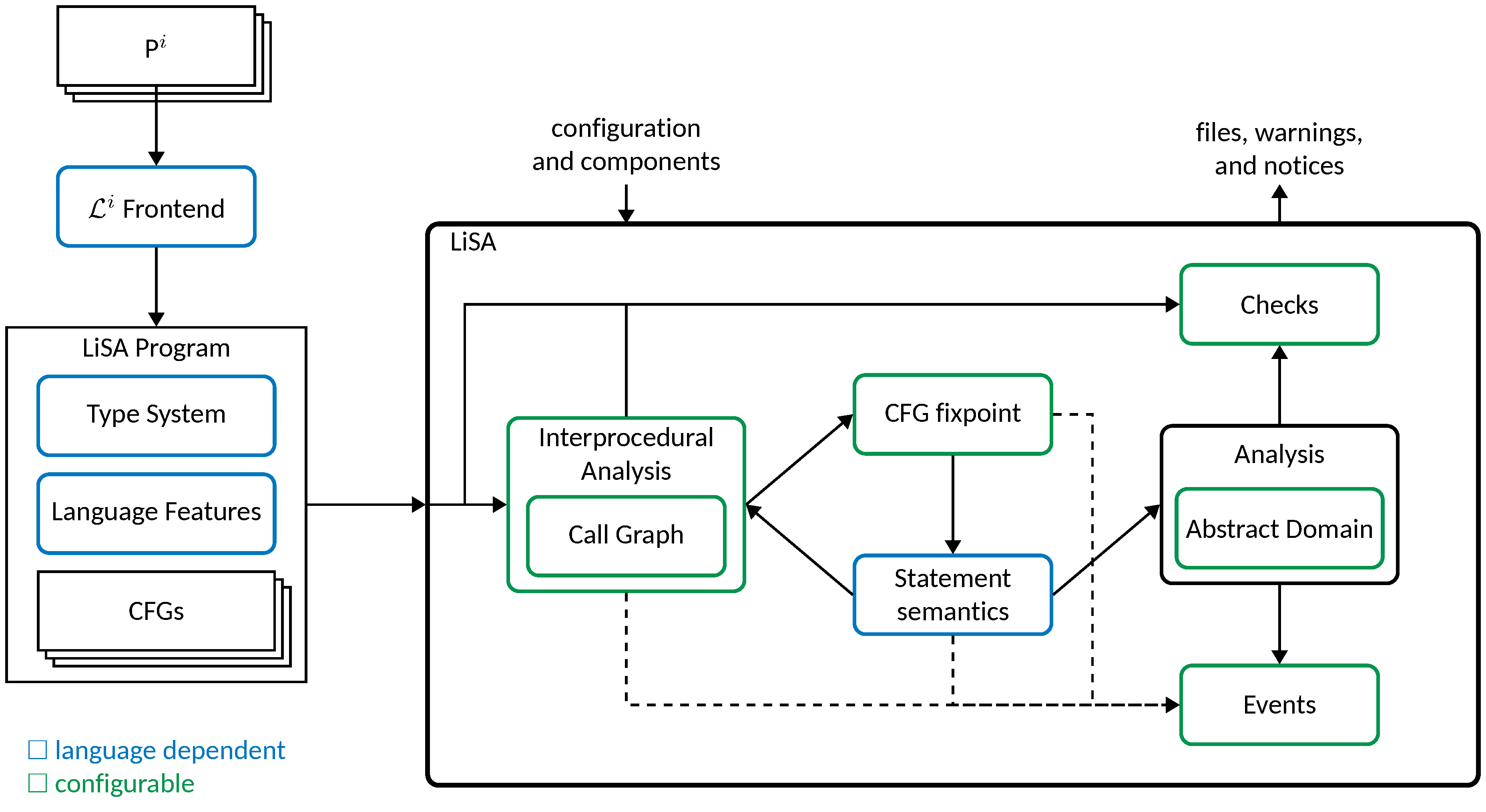
Intuitively, the analysis starts on a program P, written in a programming language i, composed by a set of files. The Frontend for language i parses the source files of P and translates them into a LiSA’s Program, which is a mainly composed by a set of control flow graph (CFGs). To keep things simple, we assume that the program is written in a single language, but the process can be extended by combining multiple frontends. The CFGs are then passed to LiSA, where the analysis starts.
The analysis begins by applying some validation checks on the program to ensure its correctness. Then, the Syntactic Checks provided in the configuration are executed, which inspect the program’s structure without performing any semantic analysis. After that, the Interprocedural Analysis is carried out, which computes a whole-program fixpoint. Such a fixpoint is computed by analyzing each CFG in the program, delegating to each Statement (the nodes of the CFG) the task of defining how it affects the program state. Each statement can perform a combination of operations, since it represent high-level constructs (e.g., calls, conditionals) rather than low-level instructions (e.g., arithmetic operations, comparisons). Each operation is either:
- a call to some other CFG, in which case the statement delegates back to the Interprocedural Analysis the computation of the result;
- an atomic operation whose effect depends on the abstract domain used for the analysis, in which case the statement forwards the operation (in the form of a Symbolic Expression) to the abstract domain currently in use.
Upon delegation to the Interprocedural Analysis, the latter computes the result of the call by analyzing each possible target. Target resolution is performed by the Call Graph, which computes all possible call targets by relying on both the program structure and the language-specific algorithms for call resolution (part of the Language Features). This process enables the simplification of abstract domains, as they do not need to handle call resolution on their own.
When a global fixpoint is reached, the analysis ends. The results of the analysis are then passed to the Semantic Checks, which inspect the analysis results to detect potential issues in the program. Finally, the Outputs of the analysis are generated, which include warnings, graphs, and reports. During the whole analysis, each component can emit Events to an event queue, where registered listeners can process them, either synchronously or asynchronously, to produce messages, logs, output files, or implement any custom behavior.
In the schematics above, components with blue borders are language-dependent, meaning that they must be defined once for each programming language that LiSA is used to analyze. Components with green borders are language-independent and take part modularly in the analysis, allowing for easy extension and customization of LiSA’s capabilities.
A more in-depth explanation of each component can be found in the pages linked below, together wiht pointers to the corresponding classes. For a step-by-step guide on how to build each component, refer to the Get Started section.
Analysis Components
Analysis components are the building blocks of LiSA’s analysis engine. They define how the analysis is performed, how the results are produced, and the general workflow of the analysis. As highlighted by the diagram above, all components are configurable: they are defined through interfaces and abstract classes, allowing for easy extension and customization.
Lattices
The Lattice interface defines the core operations that the information
produced by the analysis must support, following the Abstract Interpretation
theory. This interface is implemented by all information produced by domains,
fixpoints, and analysis results. Despite the name of the interface, it does not
enforce a lattice structure, but rather a poset with some extra operations for
retrieving abstractions of unknown values (top elements) and unreachable or
erroneous values (bottom elements). Other operations have default
implementations, but can be overridden to construct possibly complete lattices.
LiSA also comes with common lattice implementations ready to use. Read more
about lattices in the Lattices page.
Symbolic Expressions
SymbolicExpressions represent atomic semantic operations that the program
executes. They are used to deconstruct high-level syntacitc constructs
(i.e., the Statements, that are
the instructions of the program)
that can have ambiguous meaning depending on the context into simpler operations
that have a well-defined semantics for abstract domains.
As an example, Java’s addition operator’s (+) semantics can be produce
either a NumericAddition symbolic expression (if both operands have numeric
type), or a StringConcatenation symbolic expression (if at least one of the
operands is of a string type).
SymbolicExpressions are what abstract domains analyze: this allows
domain definitions independent from the source programming language,
since domains can then interpret this symbolic expression according to
their own logic. Read more about symbolic expressions in the
Symbolic Expressions page.
Semantic Domains
The SemanticDomain interface defines the operations that an abstract domain
must implement to be used in LiSA’s analyses. It is also implemented by the
non-extensible Analysis class, that is the outer-most domain that
Statements,
Interprocedural Analysis,
and the fixpoints interact with during
the analysis. Abstract domains are responsible for defining how the program
state is manipulated during the analysis. They provide operations for handling
assignments, expressions, and conditionals. Read more about semantic domains in
the Semantic Domains page.
The Simple Abstract Domain
In LiSA, an abstract domain is responsible for tracking the whole program
state, including the values and types of variables and expressions, and the
structure of the memory. This can be a complex task, especially for languages
with rich features and constructs. To ease the development of new abstract
domains, LiSA provides the SimpleAbstractDomain class, which implements a
simplified model in which the program state is divided into three main
components:
- the memory domain, which tracks the structure of the memory;
- the type domain, which tracks the types of variables and expressions;
- the value domain, which tracks the values of variables and expressions.
This separation allows domain developers to focus on specific aspects of the program state, without worrying about the entire state management. Each component can be implemented independently, and combined to form a complete abstract domain. Read more about the simple abstract domain in the Simple Abstract Domain page.
The Interprocedural Analysis
The InterproceduralAnalysis interface defines how the whole-program analysis
is performed. It is responsible for orchestrating the analysis of each
CFG in
the program, and for computing the results of calls. These two tasks are tightly
coupled: if the analysis has to proceed top-down starting from a main function,
then calls are resolved by analyzing the target CFGs on-the-fly; if the
analysis proceeds bottom-up, then calls are resolved by retrieving pre-computed
summaries of the target CFGs. For this reason, a single entity is responsible
for both tasks. Individual CFGs are analyzed by delegating to a Fixpoint
instance, which computes the fixpoint for that specific CFG. Read more about
the interprocedural analysis in the
Interprocedural Analysis
page.
The Call Graph
Solving calls is a fundamental task in interprocedural analyses, mainly relying
on the types of the call’s parameters and on how the programming languages
matches call signatures to their targets. While the latter is fixed for a given
language (a detailed discussion is present later on this page, in the
Language Features and Type System section),
the former can be carried out in different ways. To decouple call resolution from
the interprocedural analysis, LiSA introduces the CallGraph interface, which
defines how call targets are resolved. The call graph is queried by the
interprocedural analysis whenever a call is encountered, and it returns the set
of possible targets for that call. Read more about the call graph in the
Call Graph page.
Semantics of Statements and Expressions
The aim of LiSA is to be applicable not only to several programming languages,
but also to a variety of analyses. This entails that the specification of the
semantics of the code under analysis must be independent from the abstract
domains used in the analysis. LiSA adopts an analysis-time rewriting towards
Symbolic Expressions, that allows the semantics to be tuned relying on the
invariants computed by the fixpoint engine. Each Statement and Expression
defines its own forwardSemantics and backwardSemantics methods, that
is implemented by feeding symbolic expressions to the analysis being executed.
Read more on semantics definitions in the
Instruction Semantics page.
Syntactic and Semantic Checks
A Check is simply a visitor of the program, that provides hooks to inspect
various components of the program structure. There are two types of checks:
SyntacticChecks, which inspect the program structure without relying on any semantic information;SemanticChecks, which inspect the results of the analysis to detect potential issues in the program.
Checks are executed at specific points during the analysis: syntactic checks are executed right after the validation phase, while semantic checks are executed after the interprocedural analysis has reached a fixpoint. Read more about checks in the Checks page.
Analysis Events
Several Events are emitted during the analysis, to signal the occurrence of
specific situations. Events can be consumed by EventListeners, which can
process them either synchronously or asynchronously. This mechanism allows for
decoupling the analysis from side-tasks, such as logging, output generation, or
custom behaviors. Read more about events in the
Analysis Events page.
Outputs
Several outputs can be generated by LiSA, either after the analysis completes or
during its execution. Outputs can include graphs, reports, and other support
files that provide insights into the analysis results. Outputs files are
generated using the FileManager class, that provides a simple interface for
creating and managing output files. Read more about outputs in the
Outputs page.
Program Structure
LiSA’s Program is a data structure that contains all of the code that has been
parsed from the input files, together with the
Type System and Language Features
specific to the programming language of the input code.
Units
A Unit represents a logical grouping of code, such as a source file, a class,
or a module. The Program itself is a Unit. A Unit contains a set of
code members (CFGs with a descriptor)
and a set of Globals (global
variables or constants). Read more about units in the
Units page.
Control Flow Graphs
A Control Flow Graph (CFG) represents the control flow of a single
function, method, or procedure. It is composed of
Statements (the nodes of the
graph) and Edges
(the directed connections between statements). Each CFG
has a CodeMemberDescriptor, which provides metadata about the CFG, such as its name,
its parameters, and its return type. A special kind of CFGs, called
NativeCFGs, can be used to compactly represent the behavior of library or
runtime functions. Read more about control flow graphs in the
Control Flow Graphs page.
Types
As the aim of LiSA is to be language-agnostic, no assumptions on types are made.
All types are represented by instances of the Type interface, which can be
extended to represent the types of a specific programming language.
Sub-interfaces are used to identity specific categories of types, such as primitive types,
reference types, array types, and function types. Read more about types in the
Types page.
Language Features and Type System
The LanguageFeatures interface defines language-specific algorithms and
behaviors that are required during the analysis. These include algorithms for
resolving call targets, traversing type hierarchies, and handling specific
language constructs. The TypeSystem interface defines how types are managed
and manipulated during the analysis. It provides operations for type checking,
type inference, and type compatibility. Both interfaces must be implemented for
each programming language that LiSA is used to analyze. Read more about language
features and type systems in the
Language Features and Type System
page.
Statements, Expressions, and Edges
Statements are the nodes of a CFG, representing high-level constructs such
as assignments, conditionals, loops, and calls. Each statement defines how it
affects the program state during the analysis, by providing an implementation of the
forwardSemantics() method. Expressions are Statements that evaluate to a value,
such as literals, variable accesses, and binary operations.
Edges represent the directed connections between Statements in a CFG.
Similarly to Statements, each Edge defines its own traverseForward() method,
which specifies how the edge affects the program state when traversed during
the analysis. Read more about statements, expressions, and edges in the
Statements, Expressions, and Edges page.
Frontends
Frontends are responsible for translating source code or compiled code into LiSA’s program representation. They parse the input files, build the corresponding CFGs, and assemble them into a Program instance that can be analyzed by LiSA. They also provide language-specific algorithms for, e.g., matching a call to its target or traverse a type hierarchy (see the Language Features and Type System section). Each programming language requires its own frontend, as the translation process is highly language-dependent. Read more about frontends in the Frontends page.
The IMP Language
The IMP language is a high-level, imperative, and dynamically typed programming language insipred by Java. In LiSA, it is used internally for testing analyses end-to-end, to showcase what a frontend should look like, and to provide a simple playground for prototyping new analyses. Read more about the IMP language in the IMP page.